


Mastering Multicore Programming & Debugging: Strategies for Performance & Reliability
In this article we examine the evolution of multicore processors, their growing prevalence, and the design, performance, and debugging considerations that accompany them.
Systems Performance
Performance gains in embedded systems can be achieved through sophisticated compiler optimizations, efficient hardware architectures, and, increasingly, parallel execution across multiple cores. While clever compiler algorithms can squeeze additional speed from single‑threaded code, the long‑standing assumption that clock frequencies will continue to double every few years has become untenable. The modern performance ceiling lies in the low single‑digit gigahertz range, making parallelism the most viable path to scaling.
Parallelism

Not all tasks are equally amenable to parallelization. A single person must drill a deep hole, so adding more workers to that hole does not accelerate the job; in fact, it can hinder progress. Conversely, excavating a ditch is highly parallel: several workers can dig side by side, each covering a fraction of the total effort.

That illustration depicts MIMD (Multiple Instruction, Multiple Data), where each worker (core) can perform distinct operations. With four independent workers, a task that would take one core a full minute could be finished in roughly 15 seconds.
In contrast, SIMD (Single Instruction, Multiple Data) executes the same instruction across many data elements simultaneously. SIMD is ideal for workloads with regular, repeated operations—such as image filtering or vector math—but it lacks flexibility for general-purpose computing.
These considerations underpin the rise of multicore processors: by embedding multiple full CPU subsystems on a single die, designers can scale performance linearly, provided the software is written to exploit the parallelism.
Different Types of Multicore Processing
Processors can combine cores in various ways, affecting how workloads are distributed and how the cores communicate.
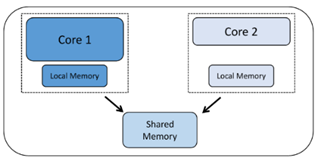
Homogeneous multicore – Two or more identical cores, each with its own registers, functional units, and often private L1 caches. Core communication typically occurs through shared memory or mailbox mechanisms. Because every core is of the same type, the same binary can run on any of them.
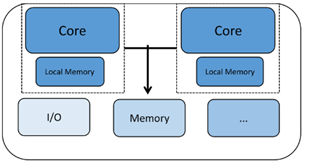
Heterogeneous multicore – A mix of different core types, each optimized for a particular workload. For example, a Bluetooth controller might dedicate one core to protocol handling while a second core manages higher‑level application logic. This architecture is common in mobile SoCs and industrial controllers.
Core distribution patterns further distinguish multicore designs:
Symmetric multiprocessing (SMP) – Multiple identical cores execute the same binary, coordinated by a real‑time operating system (RTOS). The scheduler distributes work across cores, and the binary is compiled for a single core type.
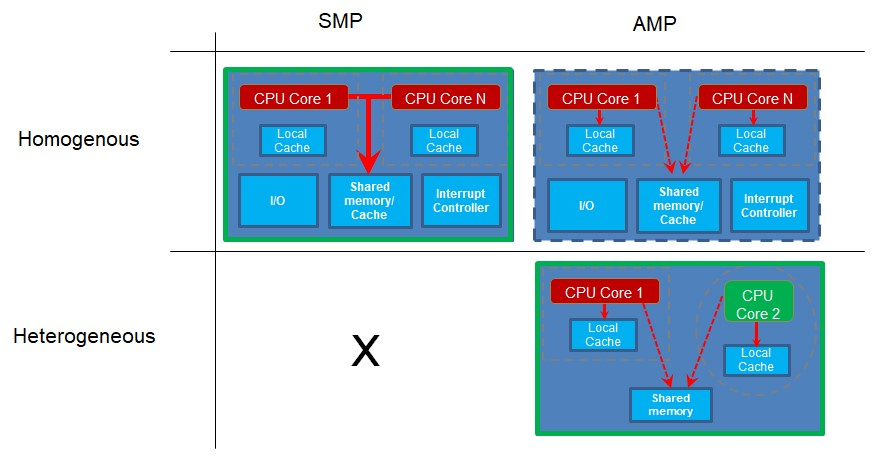
Asymmetric multiprocessing (AMP) – Each core runs its own dedicated binary. Cores may be homogeneous or heterogeneous. Communication is optional and typically handled via shared memory or messaging primitives.
Because SMP requires a single binary, it mandates homogeneous cores. AMP can be implemented on either homogeneous or heterogeneous systems, making it ideal for applications that need distinct, specialized workloads.
Reasons for Using Multicore
As Moore’s law slows, the most effective path to higher performance is to pack more cores onto a die. While clock speeds have plateaued in the low‑single‑digit GHz range, transistor densities continue to climb, enabling richer interconnects and larger on‑chip caches. Multicore designs unlock the full potential of this densification.
Heterogeneous AMP is especially powerful for real‑time and throughput‑centric workloads. By isolating time‑critical functions on a dedicated core, designers can meet strict latency guarantees without compromising overall system throughput. This separation also simplifies certification, because the real‑time component can be verified independently of the application logic.
Challenges Using Multicore
Adopting a multicore architecture introduces a host of software and system challenges:
• Task granularity – A monolithic application often cannot use multiple cores efficiently. Developers must refactor code into independent tasks that can run concurrently. Poor thread design can lead to under‑utilization or contention.
• Synchronization bottlenecks – Shared data structures and I/O devices require locks (mutexes, spinlocks, read‑write locks, etc.). Over‑aggressive locking or high contention can serialize work and negate parallel gains.
• Load imbalance – If one core finishes its work early while others lag, the idle core represents wasted compute cycles. Breaking large jobs into smaller, evenly sized chunks is essential.
• Real‑time constraints – In SMP systems, the RTOS scheduler must balance latency and throughput. Choosing between data‑partitioning (each thread processes a data block) and function‑partitioning (each thread performs a distinct stage of a pipeline) depends on the workload profile.
Debugging in Multicore Environments
Effective debugging hinges on comprehensive visibility of all cores:
• Coordinated control – The debugger should allow simultaneous or independent halting, stepping, and breakpoint setting across cores.
• Multicore trace – Capturing trace data from several cores simultaneously demands high‑bandwidth transport (e.g., CoreSight’s SWD and TPIU ports) and intelligent filtering to avoid data overload.
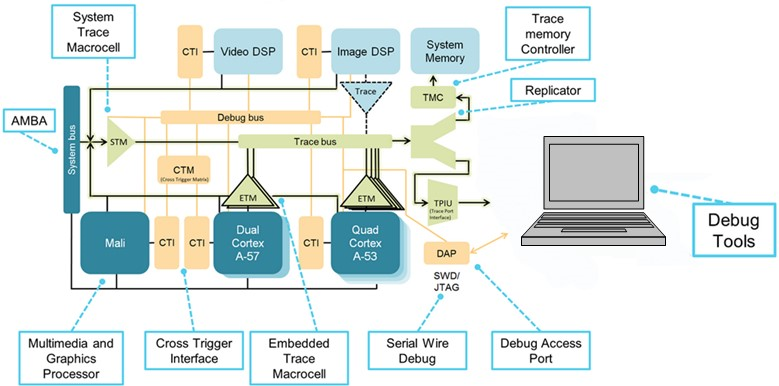
(Source: IAR Systems, diagram courtesy of Arm Ltd.)
Arm’s CoreSight debug architecture integrates cross‑trigger interfaces (CTI) and a cross‑trigger matrix (CTM), enabling the debugger to halt or trigger actions on any core in response to events from another core. This capability is essential for diagnosing race conditions and deadlocks.
The IAR Embedded Workbench C‑SPY debugger supports both SMP and AMP configurations. For SMP, the user specifies the core count and the debugger automatically connects to each core. AMP support requires two IDE instances (Master and Node) when cores run separate binaries.
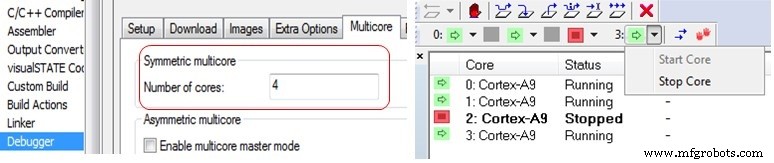
In the right‑hand view, a 4‑core Cortex‑A9 SMP cluster is displayed: core 2 is halted while the others continue executing.
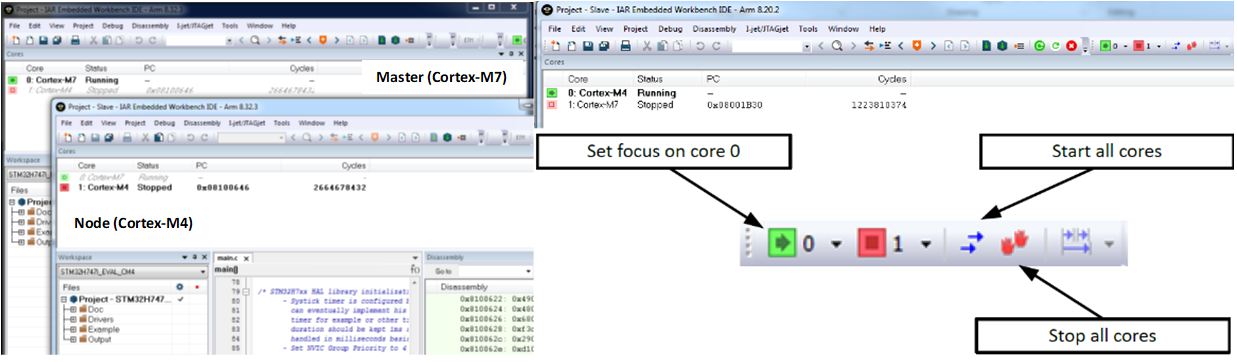
For heterogeneous systems such as the ST STM32H745/755 (Cortex‑M7 + Cortex‑M4), the debugger launches separate IDE windows for each core. Each window shows the status of its core and, optionally, the other core, allowing developers to observe inter‑core interactions in real time.
Two CTIs (system‑level, Cortex‑M4, and Cortex‑M7) are connected by a CTM, giving the debugger fine‑grained control over breakpoints and trace triggers.
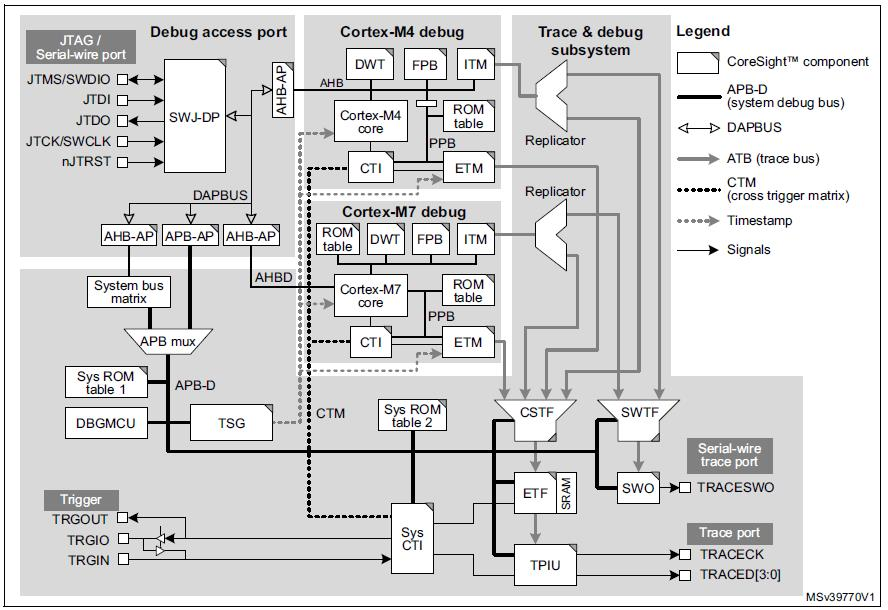
(Source: IAR Systems, diagram courtesy of STMicroelectronics from M0399 Reference manual)
Typical applications use a shared‑memory interface and a lightweight RTOS (e.g., FreeRTOS) to exchange messages between cores. From each core’s perspective, the communication appears as simple task messaging, abstracting away the underlying inter‑core mechanics.
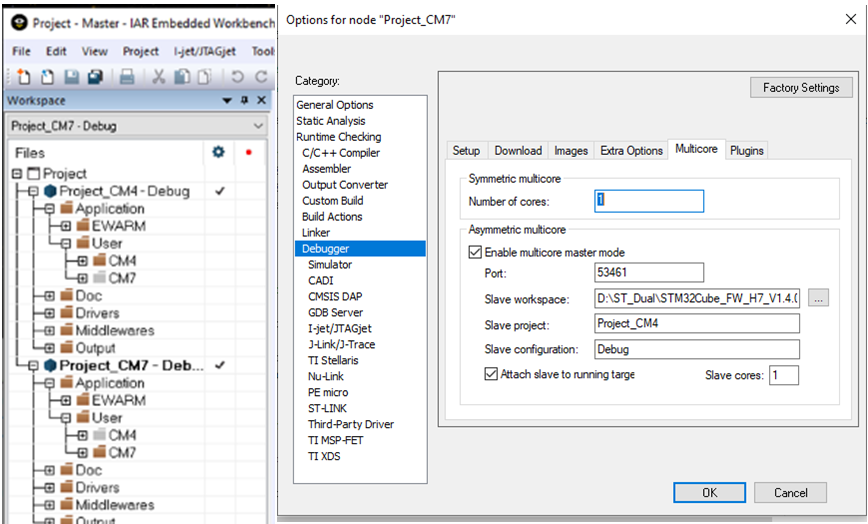
In the workspace explorer, the two projects (Cortex‑M7 and Cortex‑M4) are visible, and the user can switch focus between them. The master project automatically launches the second IDE instance, simplifying AMP debugging.
Summary
Multicore architectures deliver the performance needed as Moore’s law slows, but they demand disciplined software design and sophisticated debugging tools. Once the debug environment is configured, developers find that multicore debugging is surprisingly straightforward, especially when compared to the challenges often reported by those who have only worked with mono‑core systems.
Modern hardware and integrated software tooling now make it practical to harness multicore performance while maintaining reliability and traceability.
Note: Figure images are by IAR Systems unless otherwise noted.
 Aaron Bauch is a Senior Field Application Engineer at IAR Systems working with customers in the Eastern United States and Canada. Aaron has worked with embedded systems and software for companies including Intel, Analog Devices and Digital Equipment Corporation. His designs cover a broad range of applications including medical instrumentation, navigation and banking systems. Aaron has also taught a number of college level courses including Embedded System Design as a professor at Southern NH University. Mr. Bauch Holds a Bachelor’s degree in Electrical Engineering from The Cooper Union and a Masters in Electrical Engineering from Columbia University, both in New York, NY.
Aaron Bauch is a Senior Field Application Engineer at IAR Systems working with customers in the Eastern United States and Canada. Aaron has worked with embedded systems and software for companies including Intel, Analog Devices and Digital Equipment Corporation. His designs cover a broad range of applications including medical instrumentation, navigation and banking systems. Aaron has also taught a number of college level courses including Embedded System Design as a professor at Southern NH University. Mr. Bauch Holds a Bachelor’s degree in Electrical Engineering from The Cooper Union and a Masters in Electrical Engineering from Columbia University, both in New York, NY.
Related Contents:
- Ensuring software timing behavior in critical multicore-based embedded systems
- Multicore systems, hypervisors, and multicore frameworks
- High-performance embedded computing – Parallelism and compiler optimization
- You think your software works? Prove it!
- Software tracing in field‑deployed devices
- Compilers in the alien world of functional safety
For more Embedded, subscribe to Embedded’s weekly email newsletter.
Embedded
- Essential Breakout Boards for Raspberry Pi: I2C, UART, GPIO & More – Kits, Headers & Protection
- Navigating Challenges and Seizing Opportunities in the Aerospace Industry
- 5G & IoT: Driving Next-Gen Supply Chain Resilience
- Gartner Forecasts AI’s Next Chapter: Opportunities, Risks, and Adoption Hurdles
- Overcoming the Four Key Challenges Facing Manufacturing Departments and Job Shops
- Mastering G and M Codes: A Comprehensive Guide to CNC Programming
- Mastering Hard Turning: Overcoming Challenges with Advanced Tooling
- Metal 3D Printing: Overcoming Key Challenges & Harnessing Emerging Solutions
- Why Current Documentation Is Critical: Benefits and Challenges for Your Business
- Agile Manufacturing: Key Benefits and How to Overcome Common Challenges