


Understanding Hadoop: A Guide to Big Data Processing
The evolution of big data has produced new challenges that needed new solutions. As never before in history, servers need to process, sort and store vast amounts of data in real-time.
This challenge has led to the emergence of new platforms, such as Apache Hadoop, which can handle large datasets with ease.
In this article, you will learn what Hadoop is, what are its main components, and how Apache Hadoop helps in processing big data.
What is Hadoop?
The Apache Hadoop software library is an open-source framework that allows you to efficiently manage and process big data in a distributed computing environment.
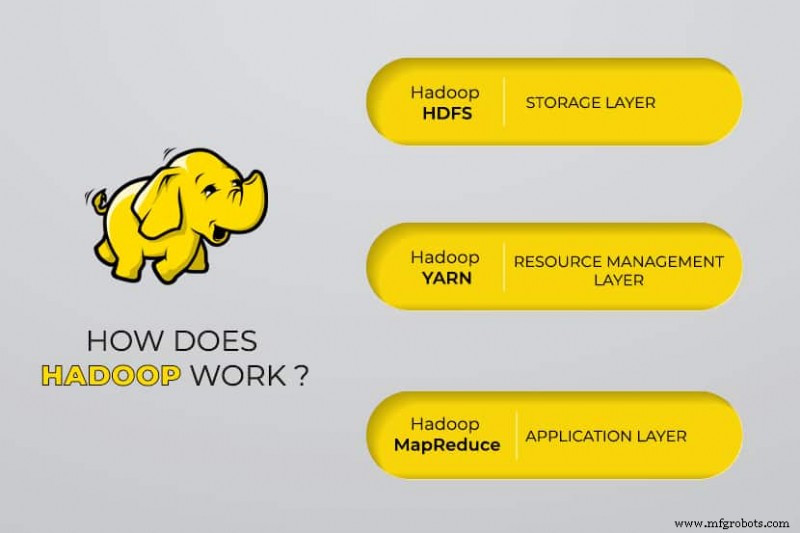
Apache Hadoop consists of four main modules:
Hadoop Distributed File System (HDFS)
Data resides in Hadoop’s Distributed File System, which is similar to that of a local file system on a typical computer. HDFS provides better data throughput when compared to traditional file systems.
Furthermore, HDFS provides excellent scalability. You can scale from a single machine to thousands with ease and on commodity hardware.
Yet Another Resource Negotiator (YARN)
YARN facilitates scheduled tasks, whole managing, and monitoring cluster nodes and other resources.
MapReduce
The Hadoop MapReduce module helps programs to perform parallel data computation. The Map task of MapReduce converts the input data into key-value pairs. Reduce tasks consume the input, aggregate it, and produce the result.
Hadoop Common
Hadoop Common uses standard Java libraries across every module.
Why Was Hadoop Developed?
The World Wide Web grew exponentially during the last decade, and it now consists of billions of pages. Searching for information online became difficult due to its significant quantity. This data became big data, and it consists of two main problems:
- Difficulty in storing all this data in an efficient and easy-to-retrieve manner
- Difficulty in processing the stored data
Developers worked on many open-source projects to return web search results faster and more efficiently by addressing the above problems. Their solution was to distribute data and calculations across a cluster of servers to achieve simultaneous processing.
Eventually, Hadoop came to be a solution to these problems and brought along many other benefits, including the reduction of server deployment costs.
How Does Hadoop Big Data Processing Work?
Using Hadoop, we utilize the storage and processing capacity of clusters and implement distributed processing for big data. Essentially, Hadoop provides a foundation on which you build other applications to process big data.
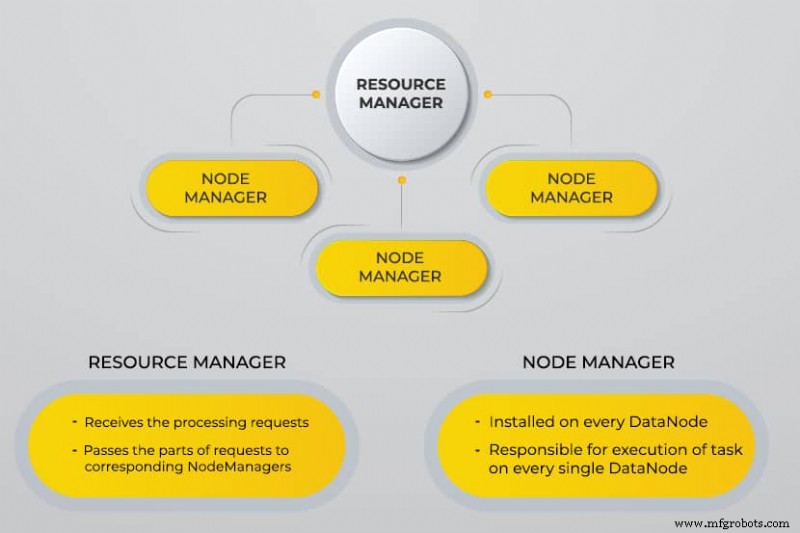
Applications that collect data in different formats store them in the Hadoop cluster via Hadoop’s API, which connects to the NameNode. The NameNode captures the structure of the file directory and the placement of “chunks” for each file created. Hadoop replicates these chunks across DataNodes for parallel processing.
MapReduce performs data querying. It maps out all DataNodes and reduces the tasks related to the data in HDFS. The name, “MapReduce” itself describes what it does. Map tasks run on every node for the supplied input files, while reducers run to link the data and organize the final output.
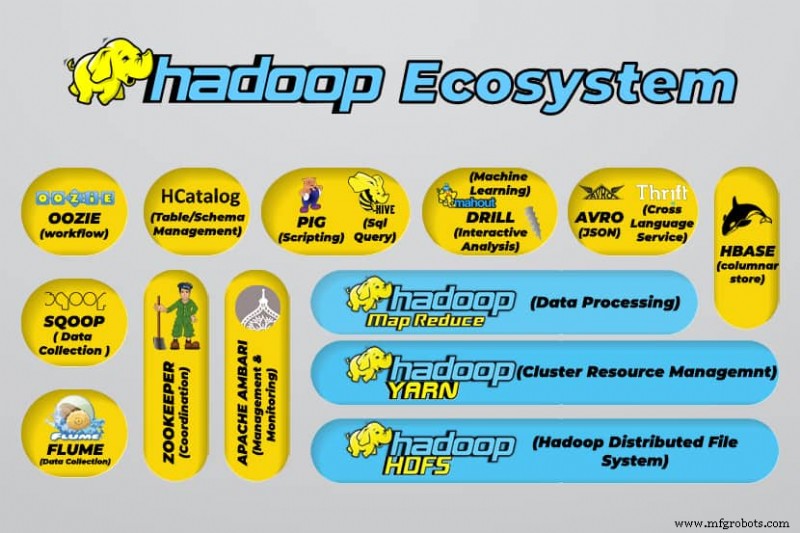
Hadoop Big Data Tools
Hadoop’s ecosystem supports a variety of open-source big data tools. These tools complement Hadoop’s core components and enhance its ability to process big data.
The most useful big data processing tools include:
-
Apache Hive
Apache Hive is a data warehouse for processing large sets of data stored in Hadoop’s file system.
-
Apache Zookeeper
Apache Zookeeper automates failovers and reduces the impact of a failed NameNode.
-
Apache HBase
Apache HBase is an open-source non-relation database for Hadoop.
-
Apache Flume
Apache Flume is a distributed service for data streaming large amounts of log data.
-
Apache Sqoop
Apache Sqoop is a command-line tool for migrating data between Hadoop and relational databases.
-
Apache Pig
Apache Pig is Apache’s development platform for developing jobs that run on Hadoop. The software language in use is Pig Latin.
-
Apache Oozie
Apache Oozie is a scheduling system that facilitates the management of Hadoop jobs.
-
Apache HCatalog
Apache HCatalog is a storage and table management tool for sorting data from different data processing tools.
Advantages of Hadoop
Hadoop is a robust solution for big data processing and is an essential tool for businesses that deal with big data.
The major features and advantages of Hadoop are detailed below:
-
Faster storage and processing of vast amounts of data
The amount of data to be stored increased dramatically with the arrival of social media and the Internet of Things (IoT). Storage and processing of these datasets are critical to the businesses that own them. -
Flexibility
Hadoop’s flexibility allows you to save unstructured data types such as text, symbols, images, and videos. In traditional relational databases like RDBMS, you will need to process the data before storing it. However, with Hadoop, preprocessing data is not necessary as you can store data as it is and decide how to process it later. In other words, it behaves as a NoSQL database. -
Processing power
Hadoop processes big data through a distributed computing model. Its efficient use of processing power makes it both fast and efficient. -
Reduced cost
Many teams abandoned their projects before the arrival of frameworks like Hadoop, due to the high costs they incurred. Hadoop is an open-source framework, it is free to use, and it uses cheap commodity hardware to store data. -
Scalability
Hadoop allows you to quickly scale your system without much administration, just by merely changing the number of nodes in a cluster. -
Fault tolerance
One of the many advantages of using a distributed data model is its ability to tolerate failures. Hadoop does not depend on hardware to maintain availability. If a device fails, the system automatically redirects the task to another device. Fault tolerance is possible because redundant data is maintained by saving multiple copies of data across the cluster. In other words, high availability is maintained at the software layer.
The Three Main Use Cases
Processing big data
We recommend Hadoop for vast amounts of data, usually in the range of petabytes or more. It is better suited for massive amounts of data that require enormous processing power. Hadoop may not be the best option for an organization that processes smaller amounts of data in the range of several hundred gigabytes.
Storing a diverse set of data
One of the many advantages of using Hadoop is that it is flexible and supports various data types. Irrespective of whether data consists of text, images, or video data, Hadoop can store it efficiently. Organizations can choose how they process data depending on their requirement. Hadoop has the characteristics of a data lake as it provides flexibility over the stored data.
Parallel data processing
The MapReduce algorithm used in Hadoop orchestrates parallel processing of stored data, meaning that you can execute several tasks simultaneously. However, joint operations are not allowed as it confuses the standard methodology in Hadoop. It incorporates parallelism as long as the data is independent of each other.
What is Hadoop Used for in the Real World
Companies from around the world use Hadoop big data processing systems. A few of the many practical uses of Hadoop are listed below:
-
Understanding customer requirements
In the present day, Hadoop has proven to be very useful in understanding customer requirements. Major companies in the financial industry and social media use this technology to understand customer requirements by analyzing big data regarding their activity.
Companies use that data to provide personalized offers to customers. You may have experienced this through advertisements shown on social media and eCommerce sites based on our interests and internet activity. -
Optimizing business processes
Hadoop helps to optimize the performance of businesses by better analyzing their transaction and customer data. Trend analysis and predictive analysis can help companies to customize their products and stocks to increase sales. Such analysis will facilitate better decision making and lead to higher profits.
Moreover, companies use Hadoop to improve their work environment by monitoring employee behavior by collecting data regarding their interactions with each other. -
Improving health-care services
Institutions in the medical industry can use Hadoop to monitor the vast amount of data regarding health issues and medical treatment results. Researchers can analyze this data to identify health issues, predict medication, and decide on treatment plans. Such improvements will allow countries to improve their health services rapidly. -
Financial trading
Hadoop possesses a sophisticated algorithm to scan market data with predefined settings to identify trading opportunities and seasonal trends. Finance companies can automate most of these operations through the robust capabilities of Hadoop. -
Using Hadoop for IoT
IoT devices depend on the availability of data to function efficiently. Manufacturers and inventors use Hadoop as the data warehouse for billions of transactions. As IoT is a data streaming concept, Hadoop is a suitable and practical solution to managing the vast amounts of data it encompasses.
Hadoop is updated continuously, enabling us to improve the instructions used with IoT platforms.
Other practical uses of Hadoop include improving device performance, improving personal quantification and performance optimization, improving sports and scientific research.
What are the Challenges of Using Hadoop?
Every application comes with both advantages and challenges. Hadoop also introduces several challenges:
-
The MapReduce algorithm isn’t always the solution
The MapReduce algorithm does not support all scenarios. It is suitable for simple information requests and issues that be chunked up into independent units, but not for iterative tasks.
MapReduce is inefficient for advanced analytic computing as iterative algorithms require intensive intercommunication, and it creates multiple files in the MapReduce phase. -
Completely developed data management
Hadoop does not provide comprehensive tools for data management, metadata, and data governance. Furthermore, it lacks the tools required for data standardization and determining quality. -
Talent gap
Due to Hadoop’s steep learning curve, it can be difficult to find entry-level programmers with Java skills that are sufficient to be productive with MapReduce. This intensiveness is the main reason that the providers are interested in putting relational (SQL) database technology on top of Hadoop because it is much easier to find programmers with sound knowledge in SQL rather than MapReduce skills.
Hadoop administration is both an art and a science, requiring low-level knowledge of operating systems, hardware, and Hadoop kernel settings. -
Data security
The Kerberos authentication protocol is a significant step towards making Hadoop environments secure. Data security is critical to safeguard big data systems from fragmented data security issues.
Conclusion
Hadoop is highly effective at addressing big data processing when implemented effectively with the steps required to overcome its challenges. It is a versatile tool for companies that deal with extensive amounts of data.
One of its main advantages is that it can run on any hardware and a Hadoop cluster can be distributed among thousands of servers. Such flexibility is particularly significant in infrastructure-as-code environments.
Cloud Computing
- Big Data and Cloud Computing: How They Work Together
- Harnessing Data in the Internet of Reliability: Strategies for Effective Management
- Maximizing Value from Big Data: Strategies for Manufacturing Success
- Industrial Internet of Things (IIoT): Definition, Scope, and Industrial Impact
- Big Data vs AI: Synergy Behind Digital Transformation
- Understanding Unique Identification (UID): Purpose, Implementation, and Benefits
- Maintenance Data Explained: The Key to Reliable Asset Management
- Data Repatriation Explained: Why Moving Cloud Data On‑Premises Matters
- Understanding Metal Processing: Turning Scrap into New Products
- Understanding Wood Processing: From Raw Timber to Finished Products