


IBM’s New Low‑Precision AI Chip Achieves 25.6 TFLOPS Training & 102.4 TOPS Inference
At the 2024 ISSCC, IBM Research unveiled a 7 nm prototype that embodies years of work on low‑precision AI training and inference. The chip delivers 16‑bit and 8‑bit training, as well as 4‑bit and 2‑bit inference—well below the industry norm of 32‑bit training / 8‑bit inference.
Lowering numerical precision cuts compute and power requirements, but IBM also introduced several architectural optimizations that further boost efficiency. The key challenge is to reduce precision without harming accuracy—a problem IBM has tackled from the algorithmic level for years.
IBM’s AI Hardware Center, launched in 2019, aims to boost AI compute performance by 2.5× annually, targeting a 1,000× improvement in FLOPS/W by 2029. Such ambitious goals are driven by the explosive growth of AI models—especially trillion‑parameter NLP systems—and the growing carbon footprint of their training.
On the prototype, the 4‑core chip reaches 25.6 TFLOPS for 8‑bit training, while delivering 102.4 TOPS for 4‑bit integer inference (both measured at 1.6 GHz and 0.75 V). Lowering the clock to 1 GHz and the voltage to 0.55 V improves power efficiency to 3.5 TFLOPS/W (FP8) or 16.5 TOPS/W (INT4).
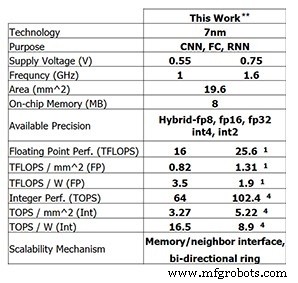
Performance of IBM Research’s test chip (Image: IBM Research) **Reported performance at 0% sparsity. (1) FP8. (4) INT4.
Low‑Precision Training
This performance builds on years of algorithmic work on low‑precision training and inference techniques. The chip is the first to support IBM’s hybrid FP8 format, introduced at NeurIPS 2019, which enables 8‑bit training while halving the compute of 16‑bit training without compromising results.
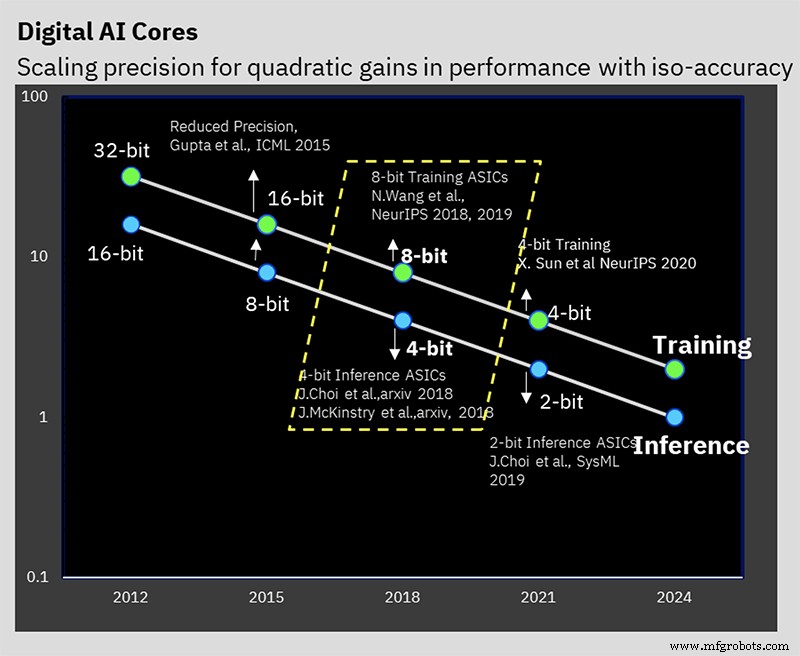
IBM Research has been working on solving the problem of maintaining accuracy while reducing precision (Image: IBM)
“Low‑precision training is challenging, but 8‑bit training is achievable with the right number formats,” said Kailash Gopalakrishnan, IBM Fellow and senior manager for accelerator architectures and machine learning. “The right numerical formats, applied to the correct tensors, are critical.”
Hybrid FP8 combines two formats: one for weights and activations in the forward pass, and another for gradients in the backward pass. Training requires both passes, whereas inference uses only the forward format.
“We found that forward tensors need higher fidelity—more precision in the mantissa—while gradients demand a wider dynamic range with a larger exponent. This trade‑off led to the 1‑4‑3 (sign‑exponent‑mantissa) split for forward and a 5‑bit exponent for backward, giving a dynamic range of 232. Our hardware now supports both variants.”
Hierarchical Accumulation
IBM’s “hierarchical accumulation” technique reduces precision during accumulation alongside weights and activations. Traditional FP16 training accumulates in 32‑bit arithmetic to preserve accuracy, but the 8‑bit scheme accumulates in FP16. By grouping long accumulations into smaller chunks and summing those, the chip minimizes rounding errors without sacrificing the benefits of lower precision.
“Adding thousands of numbers sequentially can degrade precision,” explained Gopalakrishnan. “Chunking the accumulation keeps the sum accurate while keeping the hardware lean.”
Low‑Precision Inference
While most inference engines use INT8, IBM demonstrated that 4‑bit integer arithmetic can match state‑of‑the‑art accuracy. After quantization, a quantization‑aware training step reduces the accuracy loss to less than 0.5 %, which is acceptable for many applications.
On‑Chip Ring
The chip incorporates a network‑on‑chip optimized for deep learning, enabling cores to multicast data efficiently. This reduces off‑chip memory traffic and bandwidth demands.
“We decoupled the ring’s operating frequency from the cores’, allowing independent optimization and higher core speeds without the long‑wire latency of the ring,” said Ankur Agrawal, research staff member in machine learning and accelerator architectures.
Power Management
IBM introduced a frequency‑scaling scheme that keeps the chip near its power envelope throughout the workload. By setting the initial voltage and frequency aggressively, the chip maintains high performance during compute‑heavy phases and adapts to lower demand without costly voltage changes.
“Deep learning workloads have distinct power peaks and troughs,” noted Agrawal. “Our strategy keeps power consumption steady, turning dips into performance gains.”
Test Chip
The 4‑core design balances connectivity complexity with core size, offering a scalable architecture. IBM foresees 1‑2 core chips for edge devices and 32‑64 core chips for data‑center deployments, all capable of FP16, hybrid FP8, INT4, and INT2.
“Different application domains demand different precision and energy trade‑offs,” said Gopalakrishnan. “Our Swiss‑army‑knife of formats lets us target each use case without compromising efficiency.”
Complementing the hardware, IBM Research released the “Deep Tools” compiler stack, achieving 60‑90 % utilization on the chip.
According to a prior interview, low‑precision AI chips based on this architecture should reach the market within two years.
>> This article was originally published on our sister site, EE Times.
Related Contents:
- AI chips maintain accuracy with model reduction
- Training AI models on the edge
- The race is on for AI at the edge
- Edge AI challenges memory technology
- Engineering group seeks to push 1mW AI to the edge
- Neural networks application for small‑scale tasks
- AI IC research explores alternative architectures
For more Embedded, subscribe to Embedded’s weekly email newsletter.
Embedded
- Achieving High-Precision Temperature Measurements with Advanced Silicon Sensors
- Bluetooth Mesh Design Choices: Module vs. Discrete Device
- MIT Breakthrough: 1.6 mm² Cryptographic ID Chip Combats Counterfeiting with Terahertz Backscatter
- Managing Maintenance Amid Staffing Cuts: Strategic Outsourcing & Continuous Monitoring
- Top 10 Precision Components Crafted by CNC Machine Tools
- Master Robot Programming with RoboDK – Free Comprehensive Training
- Key Factors Driving Pricing in Precision CNC Machining
- Robotics Training: Safeguarding Company Integrity and Safety
- KUKA Robots: Precision Packaging Solutions for the Food Industry
- ABB Robots: High-Speed, Precise Metal Coating Solutions