


Leveraging DSPs for Real‑Time Audio AI at the Edge
Leveraging DSPs for Real‑Time Audio AI at the Edge
Once confined to cloud servers with virtually limitless resources, machine learning is now migrating to edge devices. Lower latency, reduced cost, energy efficiency, and enhanced privacy drive this shift. For example, a self‑driving car cannot afford the delay of sending data to a cloud for pedestrian recognition, and bandwidth costs can make cloud‑based speech recognition prohibitive.
Why Edge Processing Matters
Energy trade‑offs between transmitting data and performing local inference are critical. Complex ML workloads can drain a device’s battery if not executed efficiently. Edge inference also keeps sensitive data—such as voice‑dictated emails—on the device, protecting user privacy.
Low‑Power Always‑On Voice Wake
Keyword spotting (e.g., “Hey Siri” or “OK Google”) is one of the earliest edge‑ML use cases. Running such detection on a generic application processor can consume over 100 mW, rapidly depleting a smartphone’s battery. Early phones moved the algorithm to a small DSP that ran at <5 mW, and modern smart microphones now perform the same task on a specialized audio‑ML DSP at <0.5 mW.
Beyond Voice: Expanding Edge Capabilities
Once a device supports always‑on audio ML, it can recognize contextual cues: crowded restaurants, busy streets, ambient music, ultrasonic room signatures, or nearby shouting and laughter. These features enable sophisticated use cases that benefit both the device and the user.
Building an Edge AI DSP
Top performance and energy efficiency for edge inference require tailored hardware. The most impactful techniques are summarized in the table below.
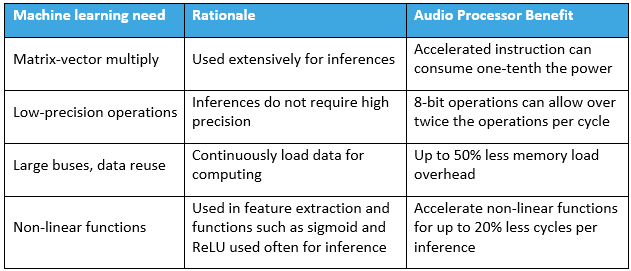
Neural‑network inference relies heavily on matrix‑vector multiplications (MVMs). A fused multiply‑accumulate (MAC) operation is the cornerstone of efficient MVM execution. Low‑precision arithmetic—often 8‑bit—is sufficient for inference, drastically reducing computational complexity. Intel and Texas Instruments, for example, offer processors with dedicated low‑precision MAC units: the TI TMS320C6745 executes 8 MACs of 8‑bit operands per cycle, while Knowles’ audio DSP can perform 16 such MACs each cycle.
Both training and inference demand significant memory bandwidth. Wide data paths alleviate pressure: Intel’s AVX‑512 supports 512‑bit transfers per cycle into a 64‑multiplier array; the TI 6745 uses a 64‑bit bus; Knowles’ processors adopt a 128‑bit bus, balancing chip area and bandwidth. Recurrent architectures (RNN, LSTM) require feedback loops, imposing additional architectural constraints that can stall heavily pipelined designs.
Audio‑ML pipelines typically start with spectral analysis and feature extraction. Accelerating classic DSP operations—FFTs, filters, trigonometric and logarithmic functions—is essential for energy efficiency. Non‑linear vector operations (sigmoid, ReLU, etc.) also benefit from single‑cycle instructions, further reducing cycle count and power.
In short, processors that fuse machine‑learning and audio‑signal acceleration enable real‑time, always‑on inference at low cost while preserving privacy. Architectural choices—multiple‑operation instruction sets, wide buses, and specialized low‑precision units—maintain high performance without high power draw. As specialized edge compute continues to evolve, the spectrum of feasible ML use cases will expand.

Jim Steele, Vice President of Technology Strategy, Knowles Corp.
© This article was originally published on EE Times: “Machine Learning on DSPs: Enabling Audio AI at the Edge.”
Internet of Things Technology
- Harnessing Machine Learning to Optimize MRO Supply Chain Management
- Enhanced Edge Audio Processing for Voice-Activated Devices
- How IIoT Transforms Packaging Machine OEMs: Boost Efficiency, Reduce Downtime, Unlock New Revenue
- Bridging the Gap: Making Machine Learning Accessible at the Edge
- Accelerating Industrial Edge Vision with NXP’s i.MX 8M Plus Processor
- NXP Accelerates Edge AI with eIQ Toolkit
- Edge AI: Why Processing Is Shifting to the Device Layer
- Deep Learning vs. Machine Learning: Understanding the Key Differences
- Machine Learning Accelerates Pipeline Safety: Real-Time Fault Detection Saves $10M
- Why Open Source Drives Innovation at the Edge – Essential eBook