


Leveraging P‑F Intervals to Predict and Prevent Failures
The potential‑to‑functional (P‑F) failure interval is a cornerstone of Reliability‑Centered Maintenance (RCM), guiding when and how to intervene before a critical failure.
Despite its importance, the P‑F interval is frequently misunderstood. Complexity spikes when a single failure mode produces multiple distinct P‑F intervals.
This article demystifies the P‑F interval and outlines a clear decision framework for managing multiple intervals.
A functional failure occurs when an asset no longer delivers a required function—whether that’s a complete halt or a partial shortfall. For example, a bearing that seizes in a fan motor will stop the fan entirely, while a worn impeller in a pump may still circulate fluid but below the necessary level. Both scenarios impact operations and must be addressed promptly.
In safety‑critical contexts, the functional failure might be a predetermined threshold that must not be exceeded. A car engine’s temperature limit is set below the point where the engine would incur irreversible damage. Exceeding that preset temperature would trigger a shutdown, preventing catastrophic failure.
Before a functional failure manifests, a potential failure presents itself as a warning sign. These symptoms—heat, vibration, odor, or cracking—can appear at different times and are detectable through various methods. For instance, a bearing’s temperature may rise before it seizes, or burnt electronics may emit a distinct odor before a component fails.
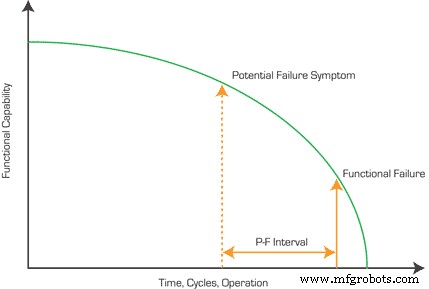
Figure 1. A graphical representation of a P‑F interval.
Senses and Sensing
The method of detecting potential failures depends on the symptom and available tools. Two broad categories exist: human senses and predictive maintenance technologies.
Human perception—eye, ear, nose, touch—remains a low‑cost, powerful diagnostic tool, especially when seasoned maintenance professionals apply it. Often, a technician can spot a problem long enough to intervene before a predictive system would, preserving valuable time.
Predictive technologies—thermography, vibration analysis, oil analysis, ultrasound—extend the detection window. Though they can identify potential failures earlier, they come with higher capital and operational costs, including equipment, consumables, and skilled technicians.
Timing is Everything
The P‑F interval is the span between first detecting a potential failure symptom and the subsequent functional failure. Since this interval varies across failure modes, it’s typically expressed as an average duration or cycle count.
Understanding the P‑F interval is essential for scheduling maintenance. A common rule of thumb is to set inspection intervals at roughly half the P‑F duration, ensuring the asset is checked before the symptom progresses to a failure.
Unlike mean time between failure (MTBF), which offers no insight into symptom‑to‑failure timing, the P‑F interval directly informs when a failure might occur, enabling proactive action.
Multiple Symptoms
When a failure mode presents multiple symptoms, each with its own P‑F interval, it’s crucial not to treat them as equivalent. For example, a bearing may first exhibit unusual vibration detectable by vibration analysis six months before failure, followed by audible changes picked up by airborne ultrasound three months out, and finally an increase in heat one month prior.
Applying the same inspection schedule to all symptoms can lead to unnecessary downtime or missed detections. Figure 2 illustrates how distinct P‑F intervals overlap and diverge.
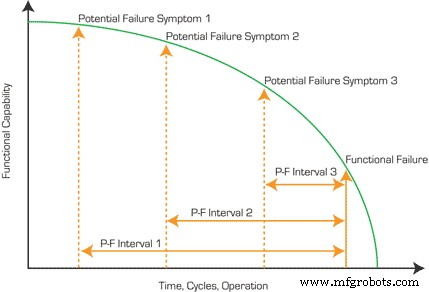
Figure 2. A graphical representation of multiple P‑F intervals.
Probability of detection (PoD) quantifies how likely an inspection will catch a potential failure if it exists at that moment. PoD depends on factors such as the failure’s location, the task’s complexity, and the skill level of the inspector. Low PoD necessitates more frequent inspections to achieve the same confidence level.
Failure Monitoring
Once a potential failure is identified, ongoing monitoring—at a tighter cadence—ensures the asset’s health is tracked until the failure threshold is reached. Effective monitoring requires a predictable, sufficiently long P‑F interval to allow additional inspections before the functional failure.
Monitoring is typically avoided when the functional failure carries safety or environmental repercussions, as the focus shifts to rapid corrective action rather than prolonged observation.
Mean time to repair (MTTR) influences the task interval. For functional failures with long MTTR—due to complex repairs, part lead times, or scarce skilled labor—the MTTR is deducted from the P‑F interval, allowing the maintenance team to intervene earlier.
Making the Right Call
Choosing the appropriate inspection tasks hinges on several factors: the available methods, required frequency, available resources, and the impact on safety and operations. A streamlined decision process involves: (1) listing viable tasks and their intervals, (2) assessing resource constraints, (3) eliminating impractical options, and (4) selecting the best fit. A formal cost‑benefit analysis can refine this choice but isn’t always mandatory.
Summary
We’ve clarified the role of P‑F intervals in RCM, highlighted the challenges of multiple intervals, and outlined a pragmatic approach to selecting inspections. P‑F intervals are a valuable asset for any maintenance program, transcending RCM to enhance overall reliability.
Robert Apelgren is a senior reliability analyst for General Dynamics. He holds a B.S. in Industrial Technology from Roger Williams University and an M.B.A. from the University of Phoenix. Robert is a Certified Maintenance and Reliability Professional (CMRP) and serves on the Society for Maintenance and Reliability Professionals’ Best Practices and Standards committees. He can be contacted at robert.apelgren@gdit.com.
Equipment Maintenance and Repair
- Leveraging Constants and Generic Maps in VHDL for Flexible Module Design
- Mastering VHDL Port Map Instantiation: A Practical Guide
- FRACAS Explained: Turning Failure Reports into Reliability Gains
- Simplify Maintenance: Leverage Basic Senses and Practical Insight
- P‑F Curve Explained: Mastering Reliability‑Centred Maintenance
- Run to Failure (RTF): When It Makes Business Sense
- Exploring IoT & Blockchain: From Tuna Tracking to Sustainable Palm Oil
- Recognizing Common Motor Rewinding Failures: Key Signs and Prevention Tips
- Streamline Failure Reporting for Maintenance Teams
- Expert Solutions for Hydraulic Cylinder Failures