


How Advanced Signal Processing Enables Seamless Voice Assistant Interaction
Smart speakers and voice‑controlled devices are rapidly expanding their reach, with assistants like Amazon’s Alexa and Google Assistant improving at deciphering our spoken commands with each update.
One of the biggest draws of this interface is its effortless nature—no learning curve, just natural conversation. Behind that smooth experience lies a sophisticated chain of signal processing steps that transform raw audio into a clear, actionable request.
In this article we examine the architecture that powers voice‑controlled solutions, revealing the hidden layers of hardware and software that bring them to life.
Signal flow and architecture
Although the specifics vary across products, the fundamental flow is consistent. Using a smart speaker such as Amazon’s Echo as an example, the key subsystems are illustrated in Figure 1.
click for larger image
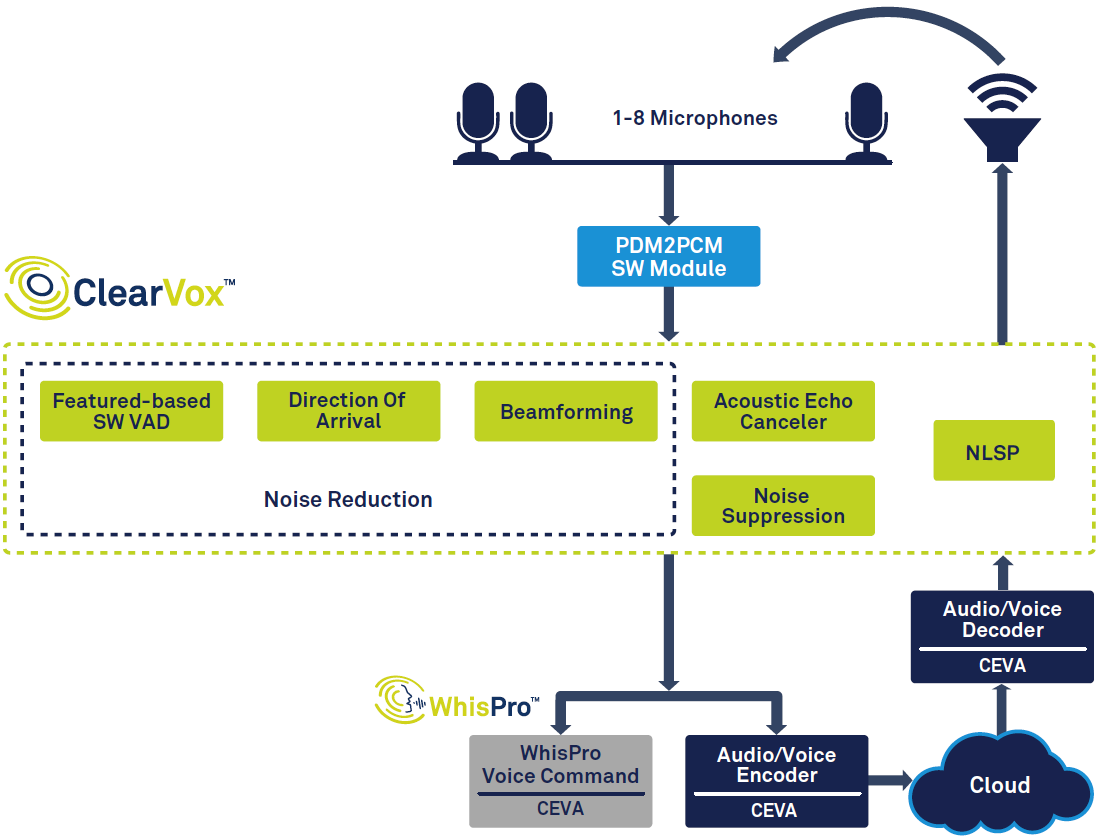
Figure 1: Signal chain for voice assistant, based on CEVA’s ClearVox and WhisPro. (Source: CEVA)
The chain begins with voice activity detection (VAD), which isolates spoken segments. The captured audio is digitized and subjected to a series of front‑end algorithms that enhance clarity by focusing on the user’s direction of arrival. The processed signal is then forwarded to back‑end speech processing, which may run partially on the device (edge) and partially in the cloud. Finally, a response—text or speech—is synthesized, decoded, and rendered through the speaker’s digital‑to‑analog path.
Different use cases introduce variations. For example, in‑vehicle voice interfaces must tackle road‑noise, while emerging wearables demand ultra‑low power and minimal cost.
Front‑end signal processing
After VAD and digitization, the device must suppress unwanted sounds. Acoustic echo cancellation (AEC) removes reflections caused by the device’s own playback, enabling seamless “barge‑in” even while music is playing. Noise suppression then cleans residual background hiss.
Voice‑controlled devices fall into two categories: near‑field (headsets, earbuds) and far‑field (smart speakers, TVs). Near‑field units typically use one or two microphones, whereas far‑field units deploy three to eight mics. The latter face a harsher acoustic environment—voices fade with distance, background noise stays constant, and reverberation complicates signal extraction.
Far‑field units employ beamforming, a technique that calculates the source direction from time differences across microphones. This allows the system to focus on the user, ignore reflections, track movement, and isolate a single speaker when multiple voices are present.
Trigger‑word detection (e.g., “Alexa”) is a critical feature. Continuous listening raises privacy concerns; therefore, many systems perform wake‑word recognition locally, sending audio to the cloud only after a full command is detected.
The cleaned voice sample is encoded before transmission to the cloud backend for deeper analysis.
Specialized solutions
Front‑end processing must be fast, accurate, and power‑efficient—especially for battery‑powered wearables. General‑purpose DSPs or CPUs struggle to meet these demands in terms of cost, size, and energy consumption. The solution is an application‑specific DSP engineered for audio tasks.
CEVA’s ClearVox is a software suite that handles multi‑mic beamforming, direction‑of‑arrival estimation, noise suppression, and AEC across diverse acoustic scenarios. Optimized for CEVA sound DSPs, ClearVox delivers a low‑cost, low‑power path to high‑quality voice capture.
Trigger‑word detection is handled by CEVA’s WhisPro, a neural‑network‑based recognizer exclusive to CEVA DSPs. WhisPro keeps the main processor asleep until a wake‑word is detected, slashing overall system power while maintaining a >95% recognition rate. It supports multiple trigger phrases and custom words, a critical factor for consumer satisfaction.
click for larger image
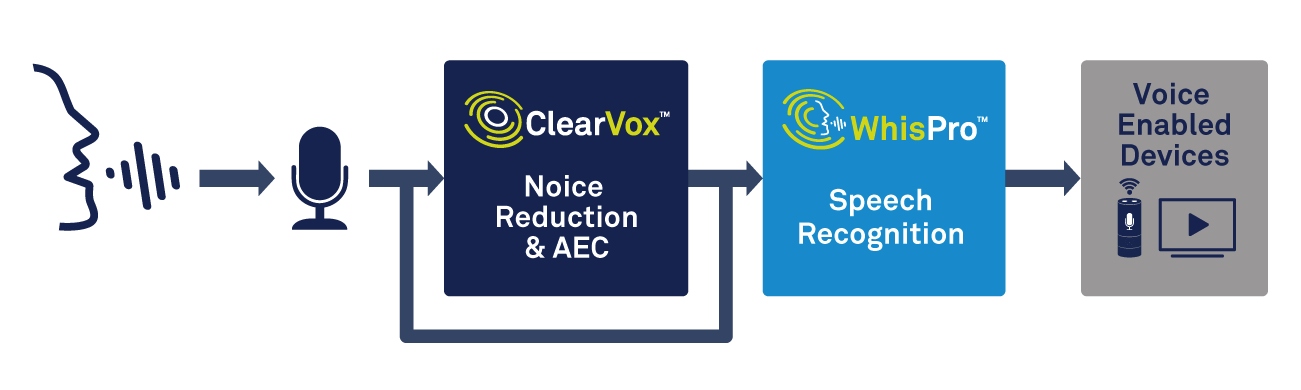
Figure 2: Using voice processing and speech recognition for voice activation. (Source: CEVA)
Speech recognition: local or cloud
Once the audio is clean and digitized, the next step is automatic speech recognition (ASR). The spectrum ranges from simple keyword spotting to full‑scale natural‑language processing (NLP). Keyword detection is ideal for narrow‑scope devices (e.g., a smart thermostat), enabling offline, instant responses.
Conversely, many applications require contextual understanding. A request like “Show me a good value hotel near the city center” must be parsed for intent, entities, and follow‑up context—a job that typically demands neural‑network inference far beyond the capability of low‑power edge chips.
Cloud‑based processing offers the computational heft to deliver sophisticated NLP, at the cost of latency and an Internet connection. Edge solutions are improving, however; CEVA’s NeuPro AI processors bring on‑device neural‑network inference to the edge, enabling smarter, faster local responses while still falling back to the cloud when necessary.
Choosing between edge and cloud involves trade‑offs. Local processing excels in speed and privacy but struggles with complex queries. Cloud processing scales to complex NLP but introduces latency and dependency on connectivity.
Conclusions
Voice interfaces are swiftly becoming a cornerstone of everyday technology. Continuous advances in signal processing, ASR, and AI—coupled with specialized hardware—are driving higher accuracy, lower power, and reduced costs.
OEMs that adopt purpose‑built solutions like ClearVox, WhisPro, and NeuPro can meet stringent performance, cost, and power targets while shortening time to market.
As voice technology matures, we can expect even more natural interaction and broader application horizons—an exciting journey that will reshape how we engage with devices.
Embedded
- How to Build and Validate IoT Business Models That Work – A Practical Guide
- Audio Edge Processors: The Key to Seamless Voice Integration in IoT Devices
- Ensuring Trustworthiness in Processor Design: Best Practices for Secure and Reliable ICs
- How Motion Tracking Drives Everyday Convenience
- How Emerging Edge AI and Microphone Advances Are Fast‑Tracking Voice Assistant Adoption
- Choosing the Right Microcontroller for High‑Performance Digital Signal Processing
- Optimize Your Supply Chain for Resilience and Efficiency Today
- Build a Real‑Time Digital Compass with Arduino & Processing
- Inkjet-Printed Graphene: The Future of 3D-Printed Electronics
- Proven Strategies to Make Your Comprehensive Safety Program Work