


Avoiding Common Pitfalls in Data Analytics Projects – A Practical Guide
Capgemini’s latest research shows that 15% of big‑data initiatives across Europe fail. To join the 85% that succeed, you must navigate the most common pitfalls with care. In this post, I’ll cover the first two major pitfalls – the remaining two are detailed in a separate article.
These challenges are universal. In our early data‑analytics workshops, we frequently encounter them from kickoff through completion. Drawing on dozens of successful projects, I’ll outline each pitfall, explain why it matters, and illustrate it with concrete examples.
1. Who Initiates the Project – IT or Business?
Data analytics and “big data” are often conflated, yet they serve different purposes. IT teams typically launch projects because they can provide the necessary infrastructure—databases, clusters, and pipelines. However, simply amassing data does not create business value.
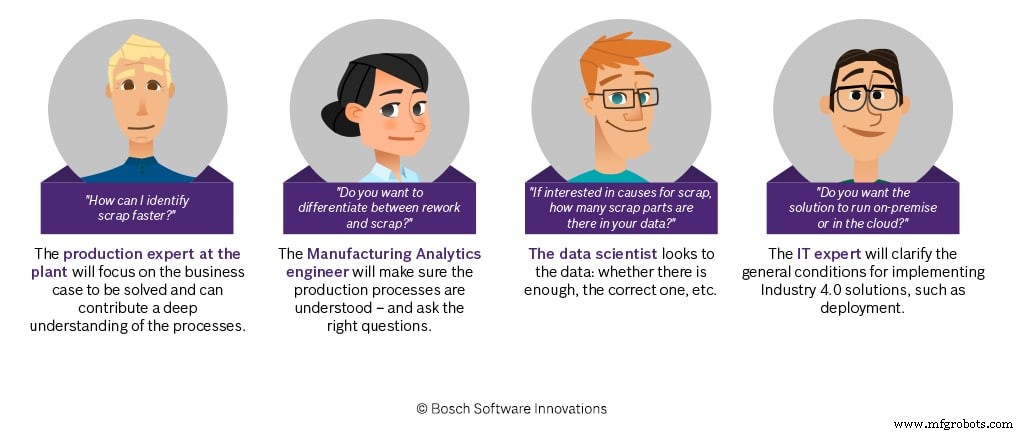
True value emerges when a non‑IT department defines clear, commercially relevant objectives. These objectives guide data scientists to focus on actionable insights rather than raw volume. Close collaboration between the business owners and data scientists is essential; the former supply domain knowledge, the latter translate it into models and visualizations.
Data‑analytics engineers act as the bridge between IT and business. Their operational experience—whether in manufacturing, logistics, or another domain—ensures that data correlates with real‑world processes (machines, sensors, workflows). The success of a project hinges on this knowledge transfer.
While IT often initiates projects, success depends on active involvement from the target department to define concrete technical and business goals.
2. Not All Data Is Created Equal
Once the project is launched, pause. Before handing the data to scientists, you must audit its quality and quantity.
a) Data Quality
Assess format consistency, source transparency, and data integrity. For multi‑source integration, a unique identifier (e.g., timestamp, part number) is crucial. Beware of heterogeneous date/time formats or unsynchronized clocks across systems—these can corrupt merges.
b) Data Quantity
More data is generally advantageous, but relevance matters. For predictive models that target rare events (e.g., failure or defect), your training set must contain enough negative instances. If the dataset is skewed, the model will struggle to learn the minority class. Extending the observation window or augmenting data can mitigate this issue.
c) The Right Data
Beyond volume, the data must contain the variables needed to meet the technical objective. For example, if you aim to predict surface roughness, the raw measurement must be captured and stored; otherwise, no model can be built. Missing critical features delay progress and inflate costs.
Ensuring Project Success
To address quality, quantity, and relevance, we provide a set of data‑quality guidelines at project inception. These guidelines, combined with early workshops that focus on quick‑win use cases, elevate manufacturing experts’ awareness and accelerate subsequent stages.
 Source: Bosch.IO
Source: Bosch.IO
Industrial Technology
- Turning Data Analytics Projects into Real-World Success: From Planning to Deployment
- Launching a Data Analytics Project in Manufacturing: A Practical Guide
- Elevating Industry 4.0: Harnessing Edge Analytics for Smarter, Faster Manufacturing
- Master Electrical Design: Optimize Projects with E3.schematic Features
- Maximizing Business Value Through Big Data & AI Integration
- Prevent Unplanned Downtime in Manufacturing with Real-Time Equipment Monitoring
- Leveraging AI to Contextualize Data Analytics for Business Insight
- Boost Decision-Making in Advanced Manufacturing Through Powerful Analytics
- Use Data Analytics to Quickly Identify and Resolve Production Issues
- Begin Your Industry 4.0 Journey: A Practical Guide