


Revisiting the Bathtub Curve: Turning Random Failure into Predictable Reliability
The “bathtub curve” has long been cited as the benchmark for understanding machine failure over time. While the basic premise is sound, the conventional depiction can mislead if taken as a literal life‑cycle model. A clearer grasp of how failure rates actually evolve enables more effective reliability strategies.
At its core, the bathtub curve is a conceptual tool that partitions failure behavior into three phases—infant mortality, a stable period, and wear‑out—based on time, cycles, or mileage. The classic flat section often overlooks the linear increase seen in many mechanical systems, which can replace the supposed constant‑rate zone.
Importantly, the curve should not be interpreted as a precise prediction for any specific machine or system. Instead, it offers a framework for anticipating the types of failure modes that may emerge at different life stages.
Reliability experts frequently assert that most equipment experiences a steady, “random” failure rate for the majority of its useful life. This period typically follows an infant mortality phase, where failures are more frequent. For mechanical assets, however, the failure rate can rise linearly over time.
What is often misunderstood is that a constant failure rate does not mean failures are truly random or uncontrollable. The appearance of randomness stems from two factors: a genuine random component in some failure modes and the superposition of many unrelated failure modes, which collectively mask underlying time relationships (see Figure 1).
By de‑aggregating failures by mode, you can uncover distinct time dependencies—some may increase, others decrease, and many may stay constant. When a clear time trend exists, proactive interventions—whether design changes, operational adjustments, or scheduled maintenance—can shift the curve and improve reliability.
In cases where a mode’s failure time follows a tight distribution and cannot be altered through design or operating changes, a hard‑time maintenance task may be the most efficient approach. While condition‑based maintenance (CBM) is the modern best practice, hard‑time actions remain valuable when the failure mode’s time dependency is well defined and predictable.
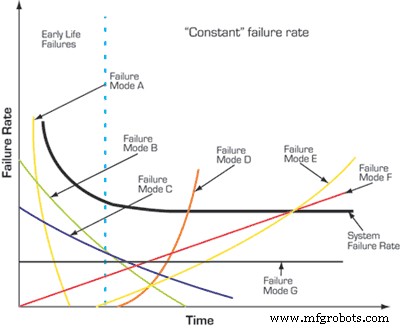
Figure 1
Beyond simplifying maintenance, identifying time‑dependent failure modes opens numerous avenues for reliability improvement:
1) Targeted Design Improvements. Failure data broken down by mode provides actionable insights for design engineers. Instead of generic reliability goals, designers receive specific evidence of weak points, enabling precise modifications that reduce future failures.
2) Early‑Life Failure Reduction. Early failures often stem from installation inaccuracies or inadequate start‑up procedures. Mode‑level data helps pinpoint these issues, allowing you to refine commissioning practices and reduce costly early life defects.
3) Optimized Monitoring Intervals. If a failure mode shows a moderate time trend that doesn’t justify a hard‑time replacement, you can adjust CBM intervals to match the rising risk, thereby catching problems before they manifest as failures.
Collecting and analyzing failure data at the mode level requires discipline but is facilitated by established standards. IEC 300‑3‑2 offers a robust field‑data collection framework, while IEC 812 supplies a standardized failure‑mode taxonomy. Feeding your data into a failure‑mode and effects analysis (FMEA) gives you a structured roadmap for action.
By abandoning the myth that the bathtub curve dictates an inevitable, random failure period, you can leverage it as a conceptual guide to identify, predict, and mitigate failures proactively.
Drew Troyer, CRE and CMRP, co‑founder and senior vice president of global services operations at Noria Corporation, brings decades of expertise in machine reliability. His career spans roles as product manager for Entek/Rockwell Automation, director of technical applications for Diagnetics Inc., and extensive consulting for clients such as International Paper, Cargill, Goodyear, Texas Utilities, Reliant Energy, and Southern Companies.
Equipment Maintenance and Repair
- The Unpredictable Challenges of Maintenance: Insights from Expert Jason Afara
- When Is It Acceptable to Deviate From a Maintenance Schedule?
- Accurately Calculating Overall Equipment Effectiveness (OEE)
- Bearing Analysis: Diagnose Issues Early, Prevent Failures
- Understanding Machine Criticality Ratings: Balancing Risk, Cost, and Design
- Selecting the Optimal Failure Analysis Technique for Reliable Equipment
- How to Cut Failure Rates in Industrial IoT Projects
- Hardness Testing in Foundries: Non-Destructive Quality Assurance
- Four Proven Strategies to Mitigate Equipment Failure Risks
- Top Reasons Hydraulic Cylinders Fail and How to Prevent Them