


Why Data Is the Cornerstone of Reliability Engineering
 In today’s technology‑driven world, data is the linchpin of strategic decisions. The discipline that harnesses this potential—data science—enables companies to gather, scrutinize, and apply information for smarter, evidence‑based choices.
In today’s technology‑driven world, data is the linchpin of strategic decisions. The discipline that harnesses this potential—data science—enables companies to gather, scrutinize, and apply information for smarter, evidence‑based choices.
Recent forecasts project the global data volume to reach 163 zettabytes by 2025—an amount equivalent to one trillion gigabytes per zettabyte. This staggering growth forces organizations to confront critical challenges in storage, quality, and governance.
This article explores why reliable data underpins rigorous reliability studies. Reliability, at its core, is the likelihood that equipment, systems, or facilities will perform without failure over a specified interval under defined operating conditions. Consequently, precise historical failure data and its proper analysis are indispensable for any credible reliability assessment.
Data analytics unlocks the potential of vast datasets, extracting actionable insights that steer better decisions. This is only achievable when the data’s integrity is unquestionable; flawed data inevitably leads to flawed conclusions.
Benefits of Data Analysis
Reliability analysis empowers managers and engineers to make informed technical and financial decisions. By analyzing data, they can refine project designs, reduce costs, predict component lifespans, investigate failures, set appropriate warranty periods, schedule effective inspections, and identify key performance indicators (KPIs). Accurate data is the bedrock of a comprehensive reliability study.
Data collection and filtration are core responsibilities of any reliability engineer. It involves systematically gathering and evaluating information on variables of interest to answer specific research questions, test hypotheses, and support actionable outcomes.
Accurate, honest data collection is the common denominator that unifies all research efforts, ensuring that every study starts from a reliable foundation.
A variety of tools and techniques can process data to enhance its accuracy and reliability—such as outlier removal, which prevents skewed results in reliability calculations.
Establishing Robust Data
In any operating facility, dependable data—covering maintenance logs, failure records, operating windows, and more—forms the basis for reliability engineering studies. Unfortunately, many companies lack the systems, processes, or culture required for effective data collection and management.
A robust database must capture and store all meaningful data points. A database that collects only a subset of essential data can deliver an incomplete, potentially misleading view of operations and asset health.
Using validated tools—methods that guarantee reliable data collection—can improve practices. For example, a Finnish company reported that roughly one in six closed maintenance reports (17.2 %) omitted a failure mode, and none recorded spare‑part details. Such gaps indicate a narrow database that fails to capture critical failure locations and impacts.
Timely data reporting is also crucial. Maintenance departments that report weekly or monthly are more likely to lose critical information than those with a dynamic system that consolidates data in real time.
A best practice is to define high‑quality data criteria within the collection and storage system, automating as much as possible to ensure consistency and searchability. Relying on open‑text fields turns analytics into a manual task; they should be reserved for supplementary detail, not primary data points.
Instead, the system should feature dedicated cells for each meaningful variable, employing drop‑down menus wherever feasible to standardize descriptions and reporting. Consistency across the database is essential for large‑scale reliability studies.
Determining the required reports and analyses first dictates which data fields to include. For reliability studies, the database should capture maintenance details on spare parts, failure modes, man‑hours, major inspection findings, damaged components, and routine activities. Structured drop‑downs in these fields enable software to calculate MTBF, availability, and other reliability KPIs automatically.
Data Quality Factors
Tools and Technology
A wide array of tools supports data quality objectives, from deduplication and data integration to migration and analytics. These tools help uncover trends and patterns by combining and categorizing raw data.
Many modern solutions are mobile‑enabled, reducing human and system errors during data capture. Adopting such technologies can markedly improve data quality.
People and Processes
Every employee—from maintenance crews to engineers and executives—must understand data’s role within the organization. This includes clarity on what data is collected, how often, and for what purposes. Training and clear processes are essential to maintain reliable and consistent data collection and storage.
Organizational Culture
Management support and a data‑driven culture are pivotal for quality. KPIs that monitor data integrity should be reported to leadership. When launching new projects or initiatives, organizations often need to adjust processes, roles, structures, and technology to capture relevant data.
Continuous improvement drives success; the quantity and quality of data fuel this engine. Ongoing training reinforces the importance of data, cultivating a culture that values accurate information.
Data’s Impact on Reliability
Consider a case study where a facility aimed to boost oil production by installing a new gas‑oil separation package (GOSP) with crude stabilization units. The GOSP comprised separation traps, wet‑crude handling, a water‑oil separator, gas compression, a flare system, transfer pumps, and stabilization units.
A reliability, availability, and maintainability (RAM) study predicted the new facility’s production availability and benchmarked it against targets. The study identified throughput bottlenecks, recommended improvements, verified operating philosophies, and outlined remedial actions or design changes.
The raw maintenance data—collected via interviews with existing crews—exhibited several issues. For instance, it suggested that every 10 months a compressor would be out of service for 30 days due to mechanical seal failures, implying a 10 % downtime attributable to seals. This assumption is inaccurate for a facility employing newer technology and lessons learned from older plants.
Likewise, the data implied a 30‑day maintenance interval every four years because of shaft pitting. Upgraded materials in the new design eliminate this problem.
Additionally, the mean time to repair (MTTR) for vibration was listed as 60 days, whereas new compressors—thanks to improved spare‑part management—achieve an MTTR of only four days.
These misaligned assumptions demonstrate how data derived from aging assets can misguide decisions for modern installations.
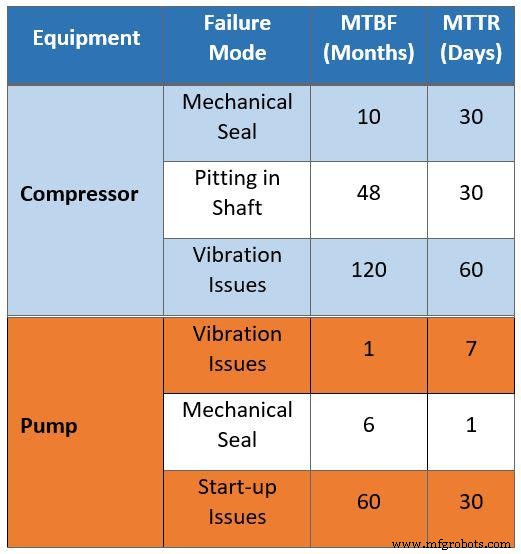 Table 1. Raw field data collected for the RAM study
Table 1. Raw field data collected for the RAM study
Table 2 presents the same dataset after filtering by reliability engineers. They removed maintenance issues that could be automatically corrected through instrumentation, then categorized the data by maintenance and operational strategies to isolate design‑related problems such as bottlenecks and capacity constraints.
The corrected data can be applied to the new facility to guide design optimization. For example, gas compressor failure modes now show an MTBF of eight years (dry seals) and an MTTR of three days. Corrosion assumptions for shaft compressors were eliminated by using upgraded materials.
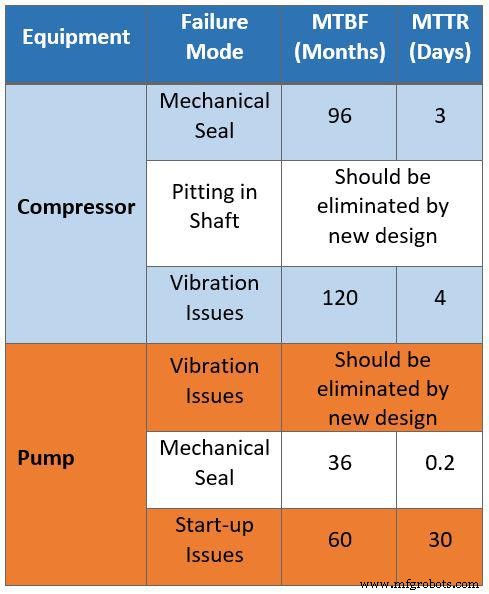 Table 2. Filtered data collected for the RAM study
Table 2. Filtered data collected for the RAM study
Figure 1 compares availability and capacity for both models based on the original and corrected datasets. The flawed data yielded an availability of 77.34 % for the new facility, whereas the corrected data projects 99 %—a stark difference that reflects reality.
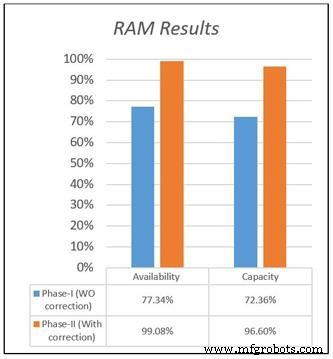 Figure 1. Availability and capacity results of the RAM study
Figure 1. Availability and capacity results of the RAM study
 Figure 2. The relationship between input data, design, and simulation outcomes
Figure 2. The relationship between input data, design, and simulation outcomes
The quality of input data determines the accuracy of any reliability model—“garbage in, garbage out.” A RAM model built on clean, well‑structured data enables optimization and precise KPI calculation.
In focused reliability studies, engineers analyze operations data to identify “bad‑actor” items—components with high maintenance costs and failure rates. Recommendations derived from incomplete or biased data risk overlooking the real issues, wasting resources on the wrong priorities.
Therefore, efficient data collection systems that clearly define required data types and quantities are essential for informed decision‑making in maintenance planning, spare‑part management, budgeting, and technical problem‑solving.
Three Key Steps to Improve Data Quality
1. Deploy the Right Database Platform
The chosen solution should enforce mandatory completion of all required fields before a maintenance notification or work order is closed. This eliminates shortcuts that compromise data consistency.
2. Integrate Existing Functions into a Unified Solution
A single platform that consolidates reliability functions reduces the number of disparate systems. For example, integrating spare‑part tracking with maintenance notifications ensures that every spare‑part movement is tied to a specific work order.
3. Implement a Data Quality Assurance Program
Regular audits of data quality across the organization are essential. A practical approach is to randomly sample 5 % of maintenance notifications and work orders at each facility, evaluate data integrity, and use findings to refine processes and system usage.
Data Is the Cornerstone
Comprehensive asset maintenance and repair history must be captured, stored, and analyzed accurately. Front‑line staff—maintenance crews and operations personnel—must recognize their critical role in ensuring data quality.
Data is the foundation of informed decision‑making, and data quality sits at the heart of every reliability study. High‑quality data empowers confident advocacy, rigorous research, strategic planning, and transparent management reporting.
About the Authors
Khalid A. Al‑Jabr is a reliability engineering specialist at Saudi Aramco with over 18 years of industrial experience focused on equipment reliability. He holds a Ph.D., is a chartered engineer, and is certified in engineering management and data analysis.
Qadeer Ahmed is a consulting reliability engineer at Saudi Aramco with 18 years of experience. A chartered engineer, he holds a Ph.D., is a Certified Maintenance & Reliability Professional (CMRP), and a Six Sigma Black Belt.
Dahham Al‑Anazi is a reliability engineering leader in Saudi Aramco’s consulting services. He has more than 25 years of technical experience and holds a doctorate in mechanical engineering.
Internet of Things Technology
- Data for All: How Democratizing Patient Data Shapes the Future of Healthcare
- Industrial Automation: A Strategic Guide for OEMs and Equipment Vendors
- Unlocking AI Value with Unlabeled Data: How Hologram Stress‑Tests Autonomous Perception
- 3 Keys to Successful Industrial IoT Deployment
- Certified Reliability Engineer (CRE): The Essential Credential for Plant Reliability Professionals
- Reliability Excellence: The Key to Safer, More Profitable Operations
- Future Outlook: Advancing Industrial IoT for Production Excellence
- Unlocking Real-Time Value: Why Your Business Must Embrace IoT
- DataOps: Streamlining Data Pipelines for Faster, Reliable Analytics
- DataOps: Revolutionizing Healthcare Automation for Cost Efficiency and Revenue Growth