


FRACAS: Turning Equipment Failures into Business Wins
In maintenance, failure is typically viewed as a negative outcome, and teams often feel the pressure of downtime metrics. Yet, this mindset can be counterproductive and unfair. Many factors—such as asset age, design limitations, or user error—are beyond immediate control. When viewed strategically, failure becomes a valuable source of insight.
“You need failure to improve,” says Thibaut Drevet, solutions engineer at Fiix and former industrial and maintenance engineer. “Failure helps you understand the systems you are maintaining, how they operate, and how you can maintain them.”
This article explains how a FRACAS—Failure Reporting, Analysis, and Corrective Action System—can turn every breakdown into a learning opportunity that drives business results.
What is FRACAS?
FRACAS is a closed‑loop reporting framework that captures, interprets, and eliminates equipment failures through three core stages:
- Failure reporting – identifying the exact asset and failure event.
- Failure analysis – extracting lessons from the incident.
- Failure correction – implementing changes that prevent recurrence.
By aggregating performance data over time, FRACAS pinpoints recurring fault patterns and informs the entire reliability strategy—from design to maintenance scheduling.
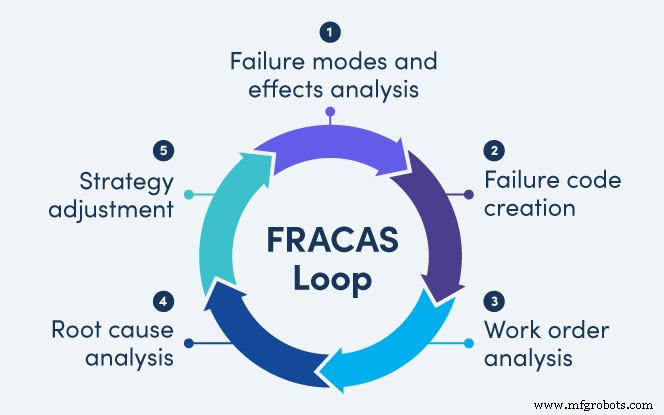
Building a FRACAS: The Continuous Loop
The FRACAS loop is a repeatable set of activities that keeps you learning and improving:
- Failure Modes and Effects Analysis (FMEA)
- Failure code creation
- Work order analysis
- Root cause analysis (RCA)
- Strategy adjustment
Failure Modes and Effects Analysis (FMEA)
FMEA is a pre‑emptive tool that lists every conceivable failure mode, its impact, and the mitigation steps. A typical FMEA contains ten key elements:
- Asset component
- Potential failure modes
- Potential failure effects
- Severity of failure
- Potential causes
- Expected frequency of failure
- Current detection and prevention processes
- Detectability
- Overall risk
- Recommended action
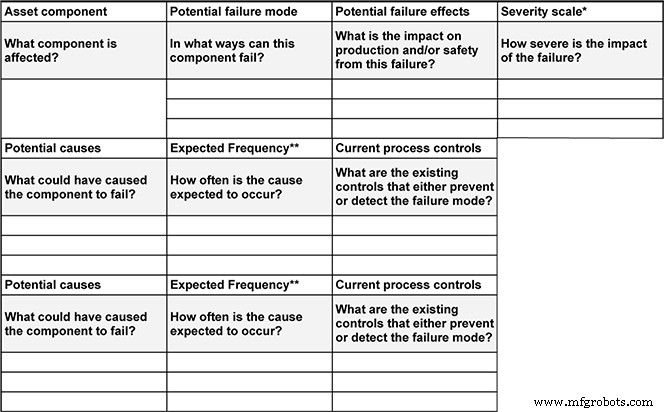
Download your own FMEA template here
FMEA is the foundation of FRACAS. It prioritizes action based on asset criticality, impact, and available resources, and it evolves as new data emerges.
Failure Code Creation
Failure codes distill complex incidents into concise identifiers—e.g., “Bearing, wear, lack of lubrication.”
- Use a clear naming convention for each part to avoid confusion.
- Group defects by condition (wear, overheating, etc.) for clarity.
- Limit pre‑loaded codes to the most common—over ten can dilute focus.
- Validate the code list with technicians to ensure relevance.
Tracking codes surfaces trends, enabling you to target the most costly failures first.
Work Order Analysis
Single incidents are nuisance; repeated patterns indicate systemic issues. By reviewing failure codes and completion notes, you can spot high‑frequency problems.
Example: Four machines logged 12 failures in six months, with 10 attributed to bearing seizure from misalignment. Reducing that count to two in the next six months signals that corrective actions are working.
Additional analysis methods are covered in our guide to work‑order data.
Root Cause Analysis (RCA)
RCA extracts long‑term value from troubleshooting. A simple fix that repeats wastes time, money, and parts.
Using the misaligned bearing example, a five‑why RCA might reveal:
- Why? The bearing was misaligned because the shaft was misaligned.
- Why? The machine was assembled incorrectly.
- Why? The technician rushed the assembly.
- Why? The technician lacked sufficient time.
- Why? The maintenance window before production was too narrow.
Thibaut advises assembling diverse teams for RCA to avoid premature conclusions.
Strategy Adjustment
Insights must translate into action. Adjustments can be minor—adding lubrication instructions—or major, such as hiring specialists for tasks beyond your team’s expertise.
- Involve technicians: Share the rationale and expected benefits. Celebrate wins, like a 40 % drop in after‑hours calls.
- Monitor outcomes: Detect unintended side effects early and iterate until success.
- Scale gradually: Test changes on one machine before rolling out across the plant.
Closing the Loop
After implementing changes, revisit the FRACAS cycle:
- Update the FMEA with new failures and mitigations.
- Audit failure codes—add, remove, or refine as necessary.
- Generate impact reports: Track reductions in failure frequency, cost savings, and scheduling improvements.
Ensuring High‑Quality Data for FRACAS
Reliable data is the lifeblood of FRACAS. Here’s how to secure it.
Create a Maintenance‑Value Culture
Data inaccuracies often stem from rushed technicians. A culture that recognizes maintenance as a production enabler encourages careful data entry.
“Maintenance isn’t the enemy of production,” says Thibaut. “When everyone sees its value, technicians take the time to log accurate information.”
Design Clear, Easy Work Orders
Ambiguous or dense work orders breed error. Simplify by including:
- Pictures and diagrams for component identification.
- Clear naming conventions.
- A concise reporting workflow.
Starter resources:
- Mastering the fundamentals: Maintenance work orders
- Designing work orders to crush your goals
- Maintenance work order template
- Equipment maintenance log template
- Preventive maintenance checklist
Automate and Integrate
Condition‑monitoring software replaces manual meter readings with real‑time data, eliminating the risk of recording a shifted value.
Integrating this data into your maintenance platform enables instant alerts and consolidated analysis.
Regular Data Audits
Monthly spot checks and technician interviews uncover systemic data gaps. Ask:
- Is any inspection task unnecessary? If so, remove or justify it.
- Do technicians know what to log and why?
- Is the data entry process user‑friendly?
Five FRACAS Reports that Drive Results
Use these reports to identify failures that hinder production and profitability.
- Failures after Start‑Up – Pinpoint issues that halt production before it begins.
- Maintenance Costs by Failure Code – Sum labor and parts costs to prioritize high‑impact failures.
- Maintenance Hours by Failure Code – Identify time‑consuming recurring fixes.
- Failures in Scheduled vs. Unscheduled Maintenance – Highlight reactive maintenance drivers.
- Failures by Shift or Site – Spot process or training gaps that can be replicated elsewhere.
Real‑World FRACAS Success Stories
FRACAS can move beyond a document and become a culture shift. Examples:
- Identifying frequent failures tied to old parts revealed a hidden cost, enabling a stronger inventory budget.
- Detection of a new failure pattern after a line change led to a revised communication process that cut downtime across multiple sites.
- Prioritizing a single high‑impact failure in the quarter secured funding to expand the technician team, clearing additional issues.
Conclusion
Building a FRACAS requires data, time, and sustained commitment. Start small, celebrate early wins, and persist. The long‑term ROI—reduced downtime, lower maintenance costs, and a more resilient operation—will justify the effort.
Equipment Maintenance and Repair
- Put the ‘I’ in Training: A Practical Blueprint for Career Growth
- Ensuring Hydraulic Fluid Purity: Key to Performance & Longevity
- Hydraulic Institute Invites Qualified Reviewers for Updated ANSI/HI 11.6 Submersible Pump Test Standard
- The Transformative Impact of Robotics on Modern Manufacturing
- Choosing the Right Fuel Storage Tank: Above‑Ground vs. Below‑Ground
- 14 Essential Maintenance Tips for Mini Excavators
- Fluke 772/773 Clamp Meters: A Modern Approach to Automation Loop Troubleshooting
- Meet Our Experts at IMVAC Europe 2018 Conference
- GearWrench Announces @Work Video Contest – Win a Free Trip to Las Vegas for SEMA 2010
- Cloud Maintenance: Unlocking Efficiency, Reliability, and Cost Savings