


FRACAS: Turning Equipment Failures into Business Gains
In maintenance circles, failure is often shunned, a word that triggers criticism and strict downtime metrics. Yet, many failure events arise from factors beyond immediate control—asset age, design choices, or operator errors. Instead of fearing failure, we can harness it as a powerful diagnostic tool.
“You need failure to improve,” says Thibaut Drevet, solutions engineer at Fiix and former industrial engineer. “Failure reveals how systems behave, guiding us to maintain them more effectively.” This article explains how a FRACAS—Failure Reporting, Analysis, and Corrective Action System—can transform mishaps into strategic advantages.
What Is FRACAS?
FRACAS is a closed‑loop reporting framework designed to eliminate recurring equipment breakdowns. It comprises three core steps:
- Failure reporting – systematically capturing each incident.
- Failure analysis – deriving lessons and root causes.
- Failure correction – implementing solutions to prevent recurrence.
By integrating historical performance data, FRACAS identifies patterns, informs maintenance strategy, and guides future design decisions.
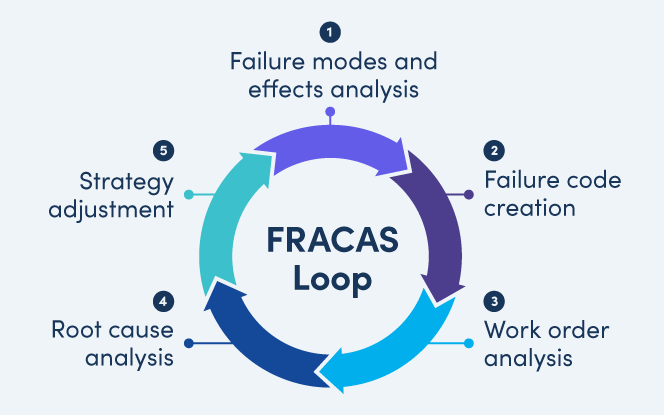
Building a FRACAS Loop
The FRACAS loop is a cyclical process that continually feeds new insights back into the system. It consists of five interlinked activities:
- Failure Modes and Effects Analysis (FMEA)
- Failure code creation
- Work order analysis
- Root cause analysis (RCA)
- Strategy adjustment
Failure Modes and Effects Analysis (FMEA)
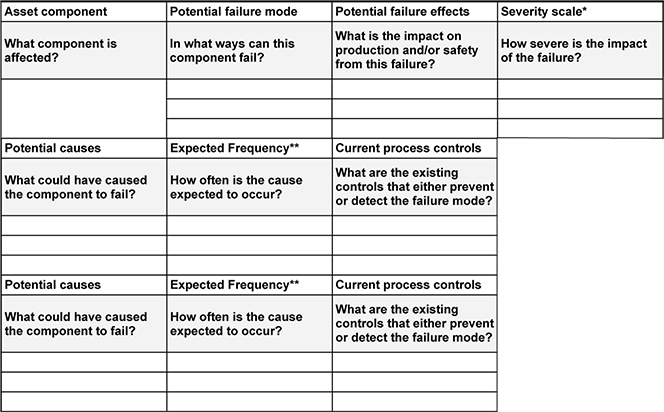
An FMEA anticipates worst‑case scenarios. It catalogs every possible failure, its impact, and corrective actions. The standard FMEA framework includes ten elements:
- Asset component
- Potential failure modes
- Potential failure effects
- Severity of failure
- Potential causes
- Expected frequency of failure
- Current detection and prevention processes
- Detectability of the failure
- Total risk assessment
- Recommended action
Download your own FMEA template here
The FMEA serves as a living baseline, updated whenever new data or insights emerge. This iterative nature keeps the FRACAS loop relevant and responsive.
Failure Code Creation
Failure codes distill complex incidents into concise descriptors that capture the part, defect, and root cause. For example, a variable‑speed conveyor might generate the code: Bearing – wear – lack of lubrication.
Best practices for coding:
- Adopt a distinct naming convention for each component.
- Group defects into clear categories (e.g., wear, overheating).
- Limit pre‑loaded codes to the most common ten; excess options dilute precision.
- Validate the code list with frontline technicians, refining as needed.
Tracking these codes reveals trend patterns, allowing teams to target the most costly or frequent failures.
Work Order Analysis
Isolated failures are nuisances; repeated, similar incidents signal systemic issues. By reviewing failure codes within work orders, you can spot high‑frequency problems. For instance, if four machines report 12 failures over six months, with 10 attributed to bearing seizure from misalignment, the data pinpoints where to focus resources.
Beyond failure codes, analyze metrics such as repair time, downtime impact, and parts cost to evaluate the true cost of recurring incidents.
Root Cause Analysis (RCA)
RCA is the bridge between troubleshooting and sustainable improvement. A quick fix—like realigning a bearing—may temporarily resolve symptoms but fails to address underlying causes. An RCA delves deeper, often using a “5 Whys” technique:
- Why was the bearing misaligned? – Because the shaft was misaligned.
- Why was the shaft misaligned? – Improper assembly.
- Why was the assembly rushed? – Insufficient scheduled maintenance time.
- Why was the time insufficient? – Production scheduling constraints.
- Why is the scheduling tight? – Inefficient planning process.
RCA requires diverse input to avoid assumptions; engaging technicians, planners, and engineers yields a holistic view.
Strategy Adjustment
Insights alone do not drive progress; action is essential. Adjustments may range from minor process tweaks—adding lubrication steps—to major organizational shifts—hiring specialists. Effective strategies include:
- Involve technicians early; explain the rationale and benefits to foster buy‑in.
- Monitor outcomes; track impact on downtime, costs, and workforce morale.
- Implement changes incrementally; pilot on one asset before scaling.
Closing the Loop
After strategy changes, revisit the FRACAS cycle to confirm improvements:
- Update the FMEA with new failure data and revised mitigation steps.
- Audit failure codes, adding new ones and retiring obsolete entries.
- Generate impact reports—failure frequency, cost savings, schedule stability—to validate ROI.
Ensuring High‑Quality FRACAS Data
Reliable data underpins every FRACAS step. To achieve this, cultivate a culture that values maintenance, streamline work orders, leverage automation, and audit regularly.
Build a Maintenance‑Positive Culture
Technicians often rush to complete jobs, compromising data integrity. When maintenance is seen as an ally to production—reducing costly downtimes—technicians allocate time for accurate logging.
Design Clear Work Orders
Unclear, cluttered orders invite misidentification and incomplete data. Start with:
- Mastering fundamentals: Maintenance work orders
- A short guide to designing work orders that help you crush your goals
- Maintenance work order template
- Equipment maintenance log template
- Preventive maintenance checklist
Automate and Integrate
Condition‑monitoring software eliminates manual meter readings, ensuring real‑time, accurate data capture. Integrating these tools with your CMMS streamlines data flow and triggers proactive maintenance.
Audit Data Monthly
Regular spot checks and technician interviews uncover data entry pitfalls. Ask:
- Are any tasks unnecessary? Remove or clarify them.
- Is the required data clear and valuable? Align everyone on key metrics.
- Is the logging process user‑friendly? Simplify complex code lists or measurements.
Five FRACAS‑Powered Reports to Drive Results
- Failures After Start‑Up – Identifies incidents that halt production before it begins.
- Maintenance Costs by Failure Code – Aggregates labor and parts expenses to prioritize high‑cost failures.
- Maintenance Hours by Failure Code – Highlights time‑consuming recurring issues.
- Scheduled vs. Unscheduled Failures – Reveals reactive maintenance burdens.
- Failures by Shift or Site – Detects process or training gaps across locations.
Real‑World FRACAS Success Stories
- Identified that aging parts caused the most failures; leveraged data to secure a higher inventory budget and cut downtime.
- Uncovered a surge in failures tied to a new product specification; established a communication protocol that reduced incidents across multiple plants.
- Prioritized three failure types, chose the most impactful one, and used success data to justify hiring additional technicians for the remaining issues.
Conclusion
Mastering FRACAS demands data, time, and unwavering commitment. Start small, celebrate wins, and keep iterating. The long‑term payoff—higher reliability, lower costs, and a proactive maintenance culture—far outweighs the initial effort.
Equipment Maintenance and Repair
- Make 2020 Your Most Productive Production Year: Proven OEE, TPM, and Data‑Driven Strategies
- Boost Your Manufacturing Facility’s Operational Efficiency: 6 Proven Strategies
- Audit Your Preventive Maintenance Schedule to Maximize Team Efficiency and Cut Costs
- Run‑to‑Failure Maintenance: When It Makes Sense & How to Plan It
- FRACAS Explained: Turning Failure Reports into Reliability Gains
- Mastering Reliability: 7 Proven Steps to Safeguard Your Manufacturing Operations
- Proven Strategies for Maintaining Industrial Manufacturing Equipment
- Proven Techniques for Corrosion Prevention in Metal Equipment
- Boost Your Construction Equipment Productivity: Proven Strategies for Efficiency and Profitability
- Professional Guide to Safely Disinfecting Construction Equipment