


Downtime Explained: Causes, Impact, and Strategies to Maximize System Availability

From laptops and conveyor belts to mining trucks and Netflix’s flagship servers, machines are the backbone of modern operations. Any period of inactivity—whether anticipated or unexpected—disrupts productivity and erodes stakeholder confidence.
In the sections that follow, we break down downtime: its definition, root causes, and practical approaches to reduce both planned and unplanned interruptions.
What is Downtime?
Downtime is any interval during which a system or piece of equipment is not available for its intended use.

Downtime can be planned—scheduled for maintenance, upgrades, or inspections—or unplanned—the result of unexpected failures, power outages, or cyber incidents.
- Unplanned downtime occurs when unforeseen events halt operations. Equipment breakdowns are the most common trigger.
- Planned downtime is a controlled pause that allows teams to perform routine maintenance, software upgrades, or safety checks.
Regardless of intent, downtime means the asset cannot fulfill its purpose for a measurable period.
Across industries—from heavy manufacturing to cloud services—downtime translates into lost revenue, strained contracts, and reputational damage.
Downtime in Manufacturing
Manufacturers, especially those reliant on asset‑intensive equipment, have long struggled with machine unavailability. When a machine stops, a line grinds to a halt, revenue slips, and supply‑chain partners may face delays.
Key performance indicators such as Mean Time To Repair (MTTR) and Mean Time Between Failure (MTBF) help track the frequency and duration of failures. While MTTR isn’t a perfect metric, it offers valuable insight when combined with other data.
Understanding the primary drivers of downtime enables targeted interventions, reducing both cost and risk.
Downtime in IT
In IT, downtime is the interval during which a network, application, or server is offline. The financial impact can be staggering—industry estimates place the average cost of a network outage at roughly $300,000 per hour.
Causes include planned maintenance, hardware or software failures, power interruptions, and cyberattacks. Even short outages can cascade into significant productivity losses.
Downtime vs. Availability
Availability measures the probability that an asset is operational when needed. It reflects the likelihood that equipment will deliver the expected output during scheduled shifts.

Availability is calculated by dividing uptime by the sum of uptime and downtime:
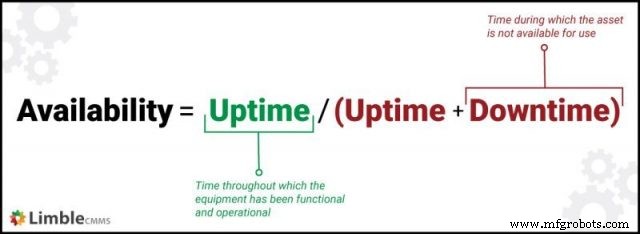
Accurate availability figures hinge on precise downtime measurement.
Common Causes of Equipment Downtime
Root‑cause analysis is essential, but many downtime events stem from a few well‑understood factors.
Operator Error
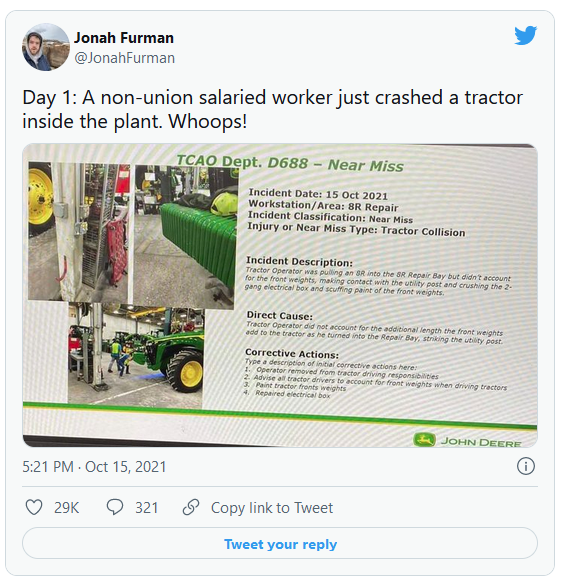
Inadequate training or high‑pressure environments often lead operators to misuse machinery, triggering breakdowns. For example, John Deere recently reported a shutdown caused by an improperly handled piece of equipment.
Insufficient Preventive Maintenance
When everything runs smoothly, teams may overlook routine checks. Early warning signs—such as vibration spikes or temperature anomalies—are often subtle and can be missed without a systematic approach.
The U.S. Department of Energy estimates that a robust preventive maintenance program can:
- Reduce maintenance costs by up to 30%.
- Cut malfunctions by 35–45%.
- Increase uptime by up to 75%.
Over‑Maintenance
Performing unnecessary shutdowns or disassemblies inflates planned downtime and introduces risks. Each maintenance window exposes equipment to potential damage—from loose fasteners to misaligned components.
Facebook’s 2021 outage illustrates how even scheduled checks can inadvertently disrupt services: “During a routine capacity assessment, a command inadvertently disconnected all of Facebook’s data centers.”
Excessive maintenance:
- Escalates costs.
- Increases wear and tear.
- Consumes valuable technician hours.
- Wastes spare parts inventory.
Modern Computerized Maintenance Management Systems (CMMS) help balance frequency with necessity.
Lack of a Reliability Culture
Under time pressure, teams may resort to quick fixes that bypass proper procedures. Without a culture that prioritizes reliability, such shortcuts become the norm, undermining long‑term uptime.
Strategies to Reduce Planned Downtime
While scheduled downtime is unavoidable, its duration can be minimized through disciplined planning.
Standardize Tasks and Boost Training
Standard Operating Procedures (SOPs) reduce variability between technicians. Coupled with rigorous onboarding, they ensure that every crew member can perform tasks efficiently and safely.
via GIPHY
Limit Excessive Maintenance
Use a CMMS like Limble to map maintenance needs against asset history, technician availability, and production schedules. This data‑driven approach prevents unnecessary downtime.
To eliminate redundant work entirely, invest in condition‑monitoring sensors and predictive‑maintenance analytics.
Leverage CMMS for Downtime Management
Cloud‑based CMMS platforms automate scheduling, inventory tracking, and documentation. With Limble CMMS, you can create custom task builders, store SOPs, and provide technicians with instant access to maintenance logs, troubleshooting guides, and safety checklists—all of which accelerate turnaround.
Strategies to Reduce Unplanned Downtime
A study by the Institute of Asset Management found that factories lose 5–20% of their revenue to unplanned downtime. Reducing these incidents can dramatically improve profitability.
Prioritize Preventive Maintenance
Identify high‑failure equipment and develop targeted maintenance plans. Proactive action remains the most effective countermeasure.
Equip Critical Operations with Redundancy
Critical processes benefit from backup machinery that can be swapped in quickly. Though initial costs are higher, the return on investment comes from minimized production gaps.
Invest in Fault‑Tolerant Equipment
Modern machines designed with built‑in fault tolerance—redundant drives, self‑diagnostic modules—naturally reduce downtime. While pricier upfront, they lower long‑term maintenance costs and downtime risk.
Establish Emergency Maintenance Protocols
Unplanned failures cannot be fully eliminated. A well‑structured emergency response—clear roles, rapid communication, and pre‑approved spare parts—ensures swift recovery.
Engage Operators in Routine Maintenance
Autonomous maintenance empowers operators to perform basic upkeep, such as cleaning, safety checks, and visual inspections. Benefits include:
- Enhanced equipment ownership.
- Earlier detection of anomalies.
- Reduced burden on specialized technicians.
Collectively, these practices lower total downtime and boost asset utilization.
Take Action Now
Downtime is not a passive phenomenon—it demands active management. Whether you’re tackling unplanned outages or optimizing planned maintenance windows, the key lies in data‑driven decision‑making.
For unplanned downtime, root‑cause analysis followed by preventive action is essential. For planned downtime, use CMMS and predictive analytics to schedule, coordinate, and execute maintenance with minimal disruption.
Limble CMMS offers a unified platform to orchestrate all maintenance activities. Interested? Schedule a demo or start a free trial today.
Equipment Maintenance and Repair
- Understanding Equipment Depreciation: Calculating Asset Useful Life & Optimizing Maintenance
- Nordson Power of Choice Programs: Cut Maintenance Costs, Reduce Downtime, and Lower TCO
- How to Cut Unscheduled Downtime: 2 Proven Strategies
- Three Proven Strategies to Cut Downtime & Boost Plant Productivity
- System Availability: Why It Matters, How to Measure, and Boost Your Production
- Criticality Analysis: Identifying & Prioritizing High‑Risk Equipment
- What Is a Machine Shop? – Understanding the Role, Equipment, and Safety Standards
- Refrigerant Charging Explained: Why Proper Gas Levels Matter
- Mechanical Room Explained: Purpose, Equipment, and Safety
- Maximize Value: Strategies for Selling or Repurposing Used Heavy Equipment