


Optimizing Hidden Layer Size to Boost Neural Network Accuracy
In this article, we’ll perform classification experiments and analyze how hidden‑layer dimensionality impacts a neural network’s performance.
Learn how adjusting the hidden layer in a Perceptron can improve accuracy, reduce training time, and maintain acceptable latency—all demonstrated with a Python implementation and real data sets.
Before diving in, review earlier posts in our neural‑network series to build a solid foundation:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
- How Many Hidden Layers and Hidden Nodes Does a Neural Network Need?
- How to Increase the Accuracy of a Hidden Layer Neural Network
The number of nodes in a hidden layer directly influences classification accuracy and training speed. Our experiments will provide data‑driven intuition for selecting a hidden‑layer size that balances speed, latency, and accuracy.
Benchmarking in Python
We’ll augment the existing Python code from Part 12 to record training and validation durations using time.perf_counter(). Below is the timing instrumentation:
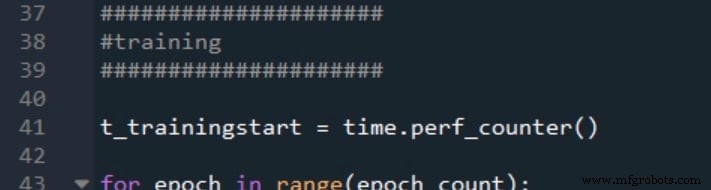
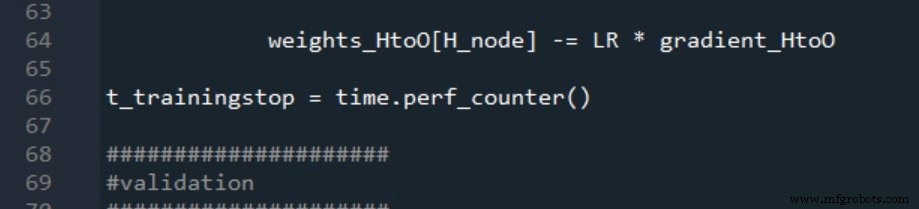
Validation timing follows the same pattern:
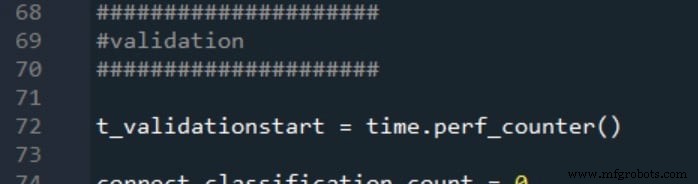

The results are reported as:
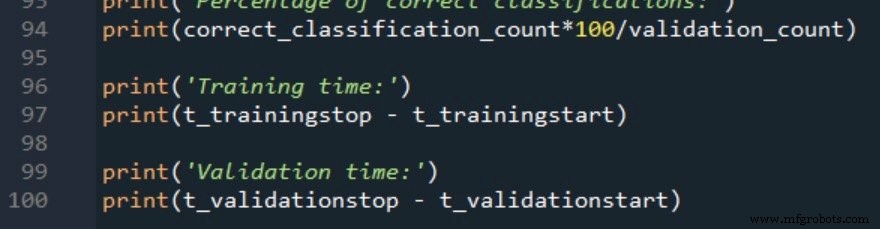
Training Data and Measurement Procedure
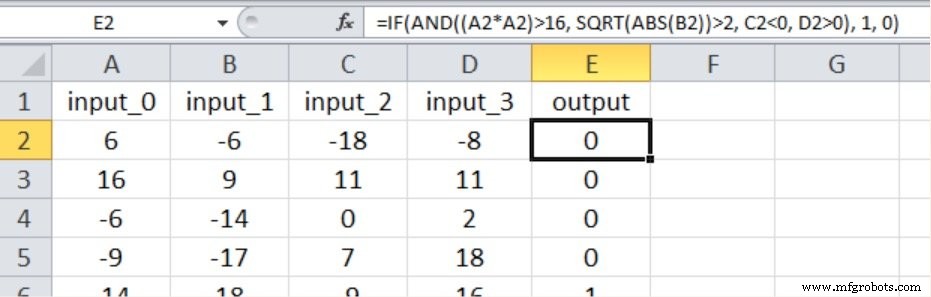
We test a binary classification task using four numeric inputs ranging from –20 to +20. The network architecture is 4‑input nodes, a single hidden layer, and one output node. Input values are generated with the Excel formula shown below:
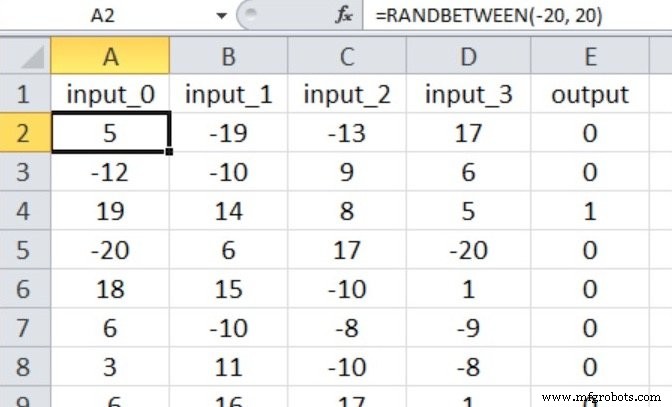
Dataset sizes: 40,000 training samples and 5,000 validation samples. We use a learning rate of 0.1 and perform one full epoch per run. Each hidden‑layer dimension is tested five times; the reported accuracy and timing are arithmetic averages.
Experiment 1: Low‑Complexity Problem
The target is true only when the first three inputs exceed zero; the fourth input is irrelevant:
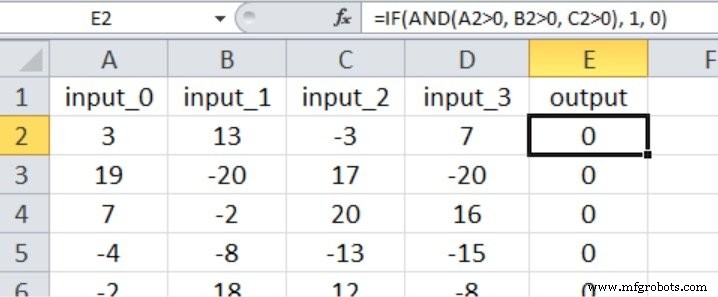
Following the guideline of two‑thirds the input size, we start with H_dim = 2. Results are summarized below:
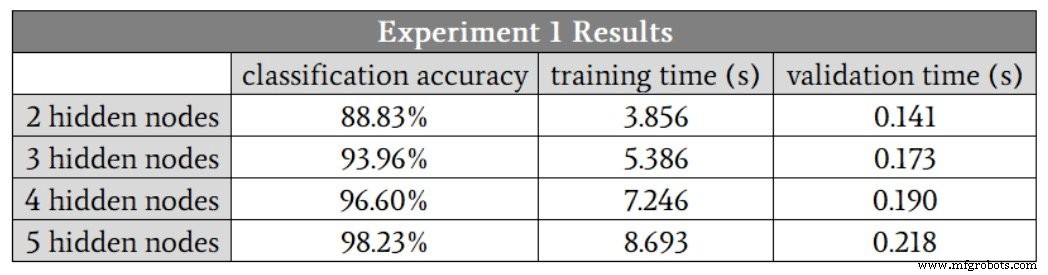
Accuracy improves up to five hidden nodes, but the marginal gain from four to five nodes is modest because one run with four nodes was an outlier (88.6 %). Removing that outlier shows four nodes slightly outperform five. Training time rises 1.9× from two to four nodes, while validation time increases only 1.3×, underscoring that training is the more computationally intensive phase.
Experiment 2: Moderate‑Complexity Problem
All four inputs influence the output, with more nuanced comparisons:
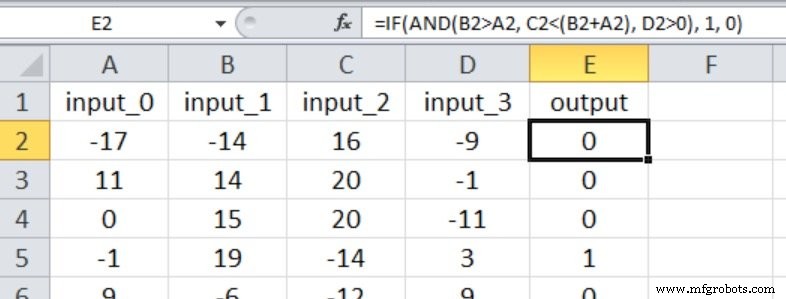
Starting with three hidden nodes, the results are:
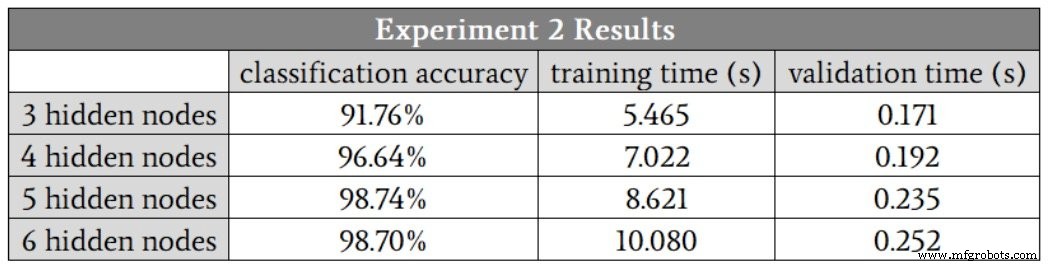
Here, five hidden nodes appear optimal, balancing accuracy and speed. Unlike Experiment 1, the runs with five and six nodes show no low‑accuracy outliers, suggesting that larger hidden layers confer robustness against training variance.
Experiment 3: High‑Complexity Problem
This scenario introduces nonlinearity: one input is squared, another is square‑rooted:
Results are as follows:
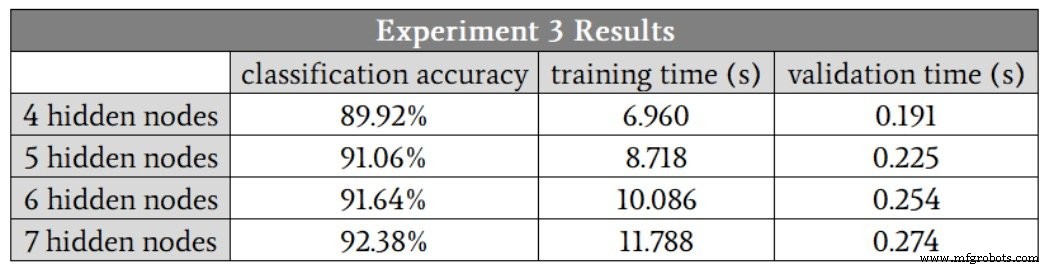
Accuracy drops compared to lower‑complexity tasks, even with seven hidden nodes. Enhancements such as adding a bias term or annealing the learning rate could improve performance, but until such changes are validated, a seven‑node hidden layer is recommended.
Conclusion
These experiments illustrate a clear trade‑off: increasing hidden‑layer dimensionality generally boosts accuracy and stability but at the cost of longer training times. Use the data‑driven insights here to inform your design choices when building Perceptron‑based classifiers.
Industrial robot
- Choosing the Right Number of Hidden Layers and Nodes in a Neural Network
- Building a Multilayer Perceptron Neural Network in Python: A Practical Guide
- Train Your Multilayer Perceptron: Proven Strategies for Optimal Performance
- Training a Basic Perceptron Neural Network with Python: Step‑by‑Step Guide
- Perceptron Basics: How Neural Networks Classify Data
- Securing the IoT from Hardware to Application: A Layer‑by‑Layer Blueprint
- Boost Shop Floor Productivity: Proven Strategies to Maximize Employee Performance
- Guarantee Accuracy in Precision Part Machining: Expert Tips & Best Practices
- Why Precision Matters: The Critical Role of Robot Accuracy in Production
- Boosting Hydraulic Pump Pressure: Proven Techniques & Tips