


Choosing the Right Number of Hidden Layers and Nodes in a Neural Network
This article offers evidence‑based guidelines for configuring the hidden portion of a multilayer Perceptron.
In previous posts of this series we covered Perceptron networks, multilayer architectures, and practical Python implementations. Before deciding on the depth and breadth of your hidden layers, you may want to review the foundational articles listed below.
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
- Choosing the Right Number of Hidden Layers and Nodes in a Neural Network
Hidden‑Layer Recap
Let’s review key points about hidden nodes:
- Single‑layer Perceptrons—networks that contain only input and output nodes—are limited to linearly separable problems. They cannot model complex relationships such as the Boolean XOR function.
- Introducing a hidden layer transforms the Perceptron into a universal approximator, enabling it to learn virtually any continuous mapping between finite input and output spaces.
- Hidden‑to‑output weights influence the final error indirectly, making training more intricate.
- Backpropagation is the standard training method: the error is propagated backwards through the network, allowing us to update all non‑output weights, regardless of the number of hidden layers.
The diagram below illustrates the basic structure of a multilayer Perceptron.
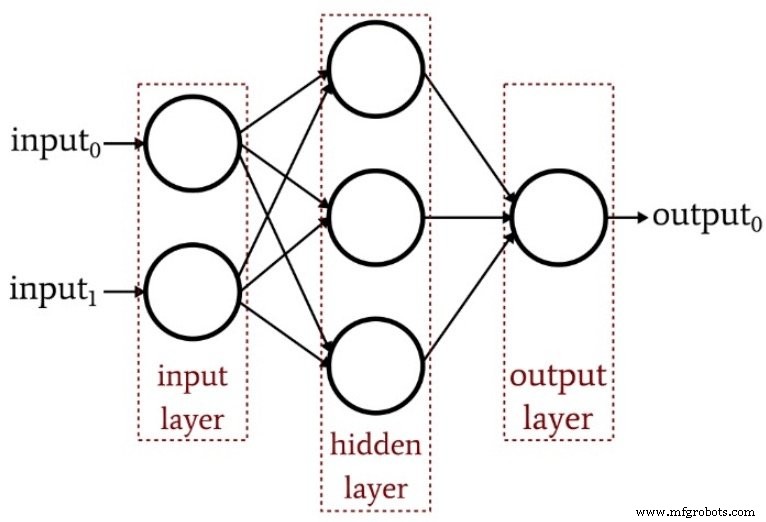
How Many Hidden Layers?
There is no one‑size‑fits‑all answer. However, a single hidden layer already endows a network with remarkable expressive power. If performance is unsatisfactory, consider tuning the learning rate, extending training epochs, or enriching the training set before adding depth.
Adding a second hidden layer increases code complexity and inference time, and it can exacerbate overfitting—especially when training data is limited.
Overfitting occurs when the network memorizes idiosyncrasies of the training set rather than learning a generalizable mapping. The following diagram visualizes this phenomenon.
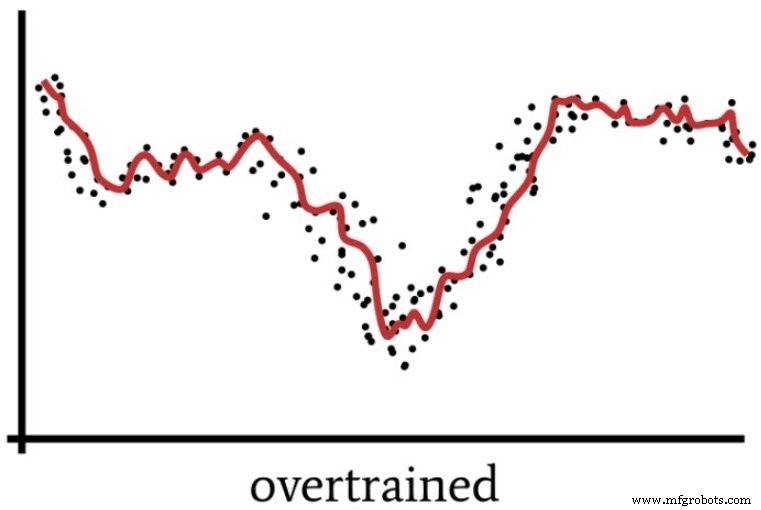
A highly parameterized network may “overthink” a problem, producing a solution that performs well on training data but poorly on unseen samples. The subsequent figure shows how excessive capacity can hinder generalization.
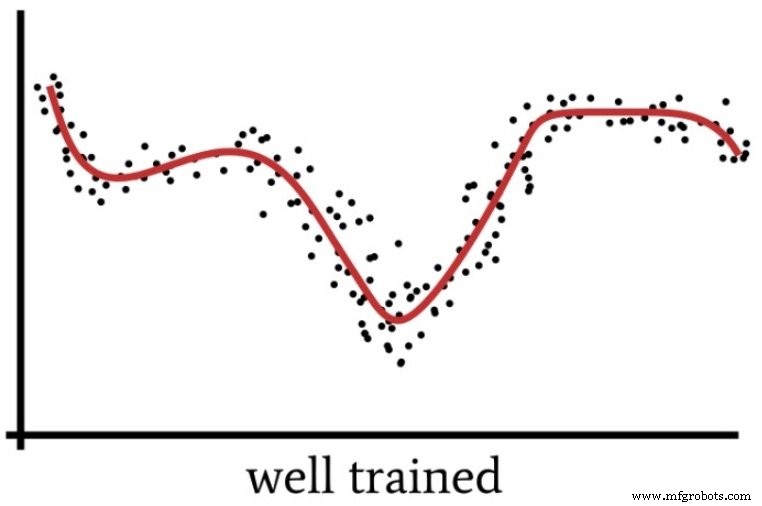
When is an extra hidden layer justified? Dr. Jeff Heaton, in his comprehensive book on neural network training, notes that a single hidden layer can approximate any continuous function between finite spaces. Adding a second layer allows the network to represent decision boundaries with arbitrary accuracy, but only when the problem complexity truly warrants it.
How Many Hidden Nodes?
Choosing the right number of nodes per hidden layer is a balance between expressiveness and overfitting risk. While experimentation is essential, Dr. Heaton provides three practical heuristics (p. 159) that serve as a solid starting point. Based on signal‑processing experience, I suggest the following guidelines:
- If the network has a single output node and the mapping is relatively simple, set the hidden dimensionality to two‑thirds of the input dimensionality.
- If there are multiple outputs or the relationship is complex, use a hidden size equal to the sum of input and output dimensions—keeping it below twice the input size.
- For extremely intricate mappings, set the hidden size to one less than twice the input dimensionality.
Conclusion
By following these principles, you can systematically configure and refine the hidden layers of a multilayer Perceptron to achieve robust performance. In our next article we’ll demonstrate how these rules translate into concrete Python code and evaluate their impact on real‑world datasets.
Industrial robot
- Adding Bias Nodes to a Multilayer Perceptron in Python
- Optimizing Hidden Layer Size to Boost Neural Network Accuracy
- Training Neural Networks with Excel: Building & Validating a Python Multilayer Perceptron
- Building a Multilayer Perceptron Neural Network in Python: A Practical Guide
- Train Your Multilayer Perceptron: Proven Strategies for Optimal Performance
- Training a Basic Perceptron Neural Network with Python: Step‑by‑Step Guide
- A Beginner’s Guide to Perceptron Neural Networks: Classifying Data with a Simple Example
- Perceptron Basics: How Neural Networks Classify Data
- Choosing the Right Number of Axes for Your Robotic Positioner
- How to Determine the Optimal GPM for Your Wood Splitter