


Fault Tolerance: Boosting Reliability, Availability, and Safety in Critical Systems
Systems that lack fault‑tolerance are inherently less reliable. For engineers focused on RAMS—Reliability, Availability, Maintainability, and Safety—designing with fault tolerance is therefore essential, especially for critical equipment where failure can jeopardize the entire system.
In this article we outline the core characteristics of fault‑tolerant systems and demonstrate how redundant design can elevate reliability.
What is fault tolerance?
Fault tolerance is the ability of a system to continue operating when a fault occurs. High‑fault‑tolerant designs—whether by hardware redundancy, software redundancy, or active monitoring—must eliminate single points of failure (SPOFs) to sustain partial or full operation.
The essence of fault‑tolerant designs
Developing a fault‑tolerant design requires an in‑depth understanding of potential failure modes across the equipment life cycle, their root causes, and the resulting impacts. Engineers must balance the desired reliability against cost and resource constraints. It is a misconception that a fault‑tolerant system must guard against every possible fault; instead, tolerance should match the fault’s criticality to achieve cost‑effective optimization.
Characteristics of fault‑tolerant systems
Creating a fault‑tolerant system involves deliberate actions at every lifecycle stage—specification, design, validation and verification (V&V), maintenance, operation, and disposal. The following techniques are commonly applied:
- Fault detection and display
- Fault diagnosis and containment
- Fault masking and compensation
1) Fault detection and display
Detection is the foundational element of any fault‑tolerant design. Without accurate fault sensing and notification, subsequent mitigation layers cannot function. For example, a tire‑pressure monitoring system (TPMS) uses a pressure sensor to alert the driver when a tire is over‑inflated. The only acceptable tolerance in this case is accurate detection and alerting; any corrective action is outside the scope of the TPMS.
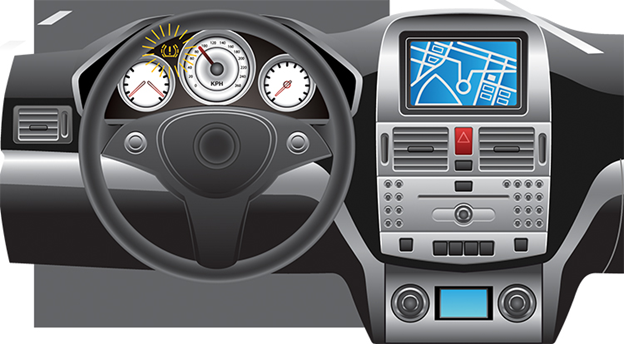
A representation of TPMS activation
2) Fault diagnosis and containment
In critical applications, detection is followed by diagnostic algorithms that locate the fault and trigger containment measures. A distributed control system (DCS) for a process plant monitors sensors, identifies abnormal pressure, and automatically opens a safety valve to vent excess pressure into a flare stack, preventing fire or explosion.
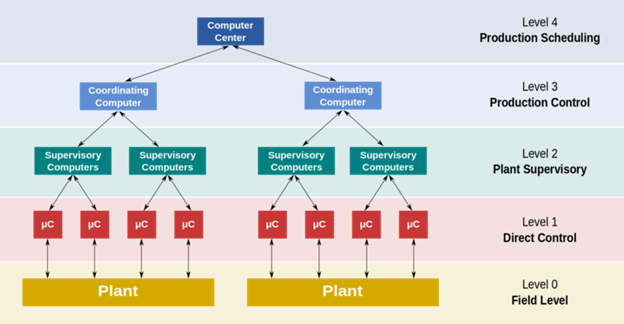
A representation of the DCS system
3) Fault masking and compensation
Fault masking is particularly valuable in IoT‑enabled equipment where cyber‑attacks can inject false data. By detecting anomalous streams and substituting correct values, the system prevents the propagation of erroneous state information. In power grids, SCADA systems monitor voltage and frequency; a cyber‑attack that manipulates these limits could trigger a power outage. Masking algorithms guard against such tampering.
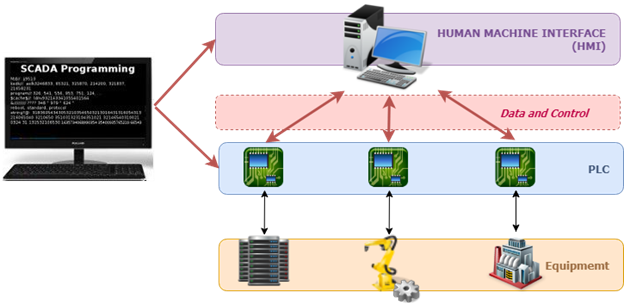
A representation of the SCADA system
Improving fault tolerance through redundant designs
Redundancy—deploying an alternate system that can assume function when the primary fails—is the most straightforward way to boost fault tolerance. However, indiscriminate redundancy can inflate cost and complexity, so the decision must be justified by a rigorous cost‑benefit analysis.
While redundancy improves fault tolerance, haphazardly adding systems should not be the objective as the amount of cost required to add any new system can significantly outweigh the attainable reliability benefit.
Redundancy types are broadly classified as active or passive.
Active redundancies
Active redundancy operates multiple units concurrently. A simple example is two pumps running at half capacity; together they achieve the target pressure. More advanced schemes—K‑of‑N redundancy and graceful degradation—allow a subset of units to remain online while others serve as hot spares, ensuring continued operation as components fail.
K‑of‑N redundancy keeps a predetermined subset of units running, enabling a larger pool of spares to take over upon failure. Graceful degradation permits system performance to decline proportionally with component loss, avoiding the need for expensive identical spare sets.
Passive redundancies
Passive redundancy places standby equipment that activates only when the primary fails. Two variants exist:
- Operating passive redundancies—hot spares that sit idle under no‑load conditions. For example, a standby alternator synchronizes automatically if the primary alternator fails.
- Non‑operating passive redundancies—cold spares that must be powered up or manually started. A municipal water pump that is switched on manually when the primary pump fails is a typical example.
Reliability techniques for analyzing fault tolerance
Analyzing fault tolerance relies on proven reliability engineering tools: Failure Mode Effect Analysis (FMEA) and Fault Tree Analysis (FTA). FMEA examines individual components from a bottom‑up perspective, while FTA models failure propagation from a top‑down view. Markov models and Monte‑Carlo simulations further quantify how failure probabilities evolve over time and how uncertainty impacts overall performance.
Fault tolerance and maintenance operations
Fault‑tolerant systems do not eliminate maintenance, but they provide a safety buffer that extends the interval between interventions. A Computer‑Aided Maintenance Management System (CMMS) remains essential to schedule corrective actions before accumulated faults precipitate a catastrophic failure. In practice, fault tolerance grants maintenance teams breathing room, allowing them to prioritize critical repairs while deferring non‑urgent work.
Despite higher upfront costs and design complexity, fault‑tolerant designs deliver measurable gains in equipment reliability and system uptime.
Equipment Maintenance and Repair
- COVID‑19 and the Cloud: How Major Providers Empowered Businesses During the Pandemic
- Operating System Fundamentals: Key Components and Functions
- Defining and Clarifying Reliability in Manufacturing Operations
- Reliability & Asset Management: Foundations for Production Excellence
- Top Performance in Maintenance & Reliability: Proven Strategies for Long‑Term Success
- Why Attention to Detail Drives Maintenance & Reliability Success
- How Motor Condition Drives Efficiency, Reliability, and Cost Savings
- ISA Releases Updated Third Edition of Control Systems Safety Evaluation & Reliability Book
- How Effective Hotel Maintenance Boosts Profits and Guest Satisfaction
- Boost Hydraulic System Reliability: Proven Strategies & Maintenance Tips