


Designing a Flexible Perceptron Neural Network in Python
Building a Perceptron for Classification: Architecture, Bias, and Activation
Welcome to the All About Circuits neural‑network series. Our previous posts have covered the theoretical foundations of neural networks:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
We’re now ready to translate this theory into a working Perceptron classification system. The following section outlines the architecture that we will implement in Python, with clear design choices that make the code portable to other languages such as C.
The Python Neural Network Architecture
The diagram below illustrates the network structure we will code:
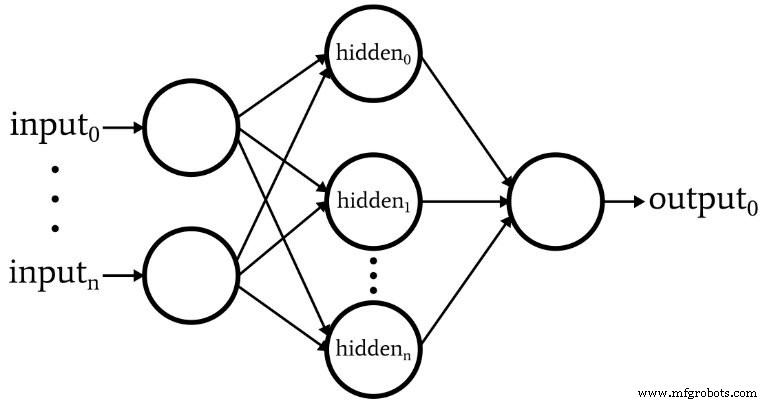
- Variable input nodes – Essential for matching the dimensionality of real‑world data.
- Single hidden layer only – A single hidden layer is sufficient for many classification tasks, simplifying the implementation.
- Variable hidden nodes – The optimal count is found empirically; we’ll discuss heuristics in a future post.
- Fixed output nodes (1) – Simplifies the initial program; future versions can support multi‑class outputs.
- Activation function – Both hidden and output layers use the logistic sigmoid: f(x)=1/(1+e^{-x}).
What Is a Bias Node? (Bias Enhances Perceptron Flexibility)
Bias nodes—or simply biases—are constants added to a node’s weighted sum before activation. They are typically set to 1 and can be placed in the input or hidden layer.
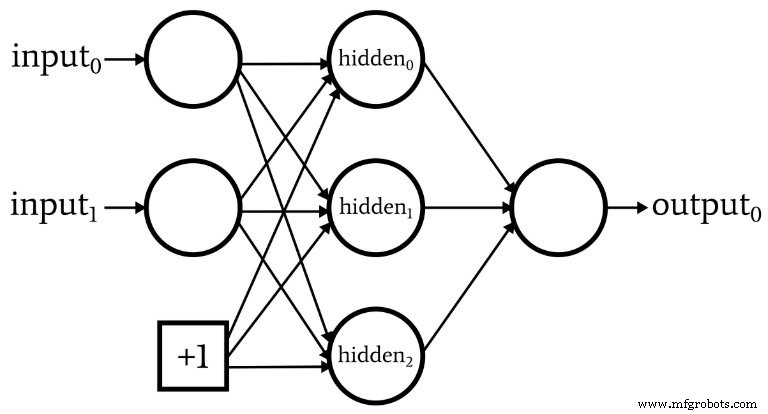
Bias weights are updated like any other weight during backpropagation. Including bias nodes allows the network to shift its decision boundary, improving performance on non‑linearly separable data.
In Part 10 of this series, we described pre‑activation as a dot product: S_preA = w · x = Σ(w_i x_i). Adding bias b modifies this to:
S_preA = (w · x) + b = Σ(w_i x_i) + b
The bias effectively acts like the y‑intercept in the linear equation y = mx + b, shifting the activation curve horizontally.
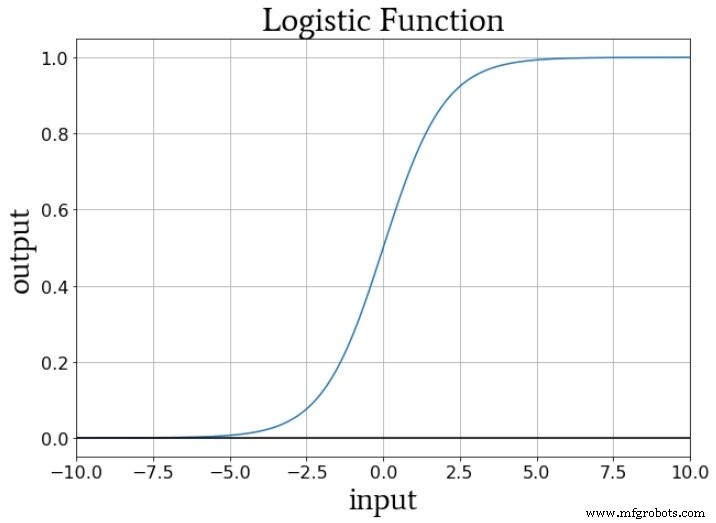
Weights, Bias, and Activation
During training, weights scale the input’s slope, while the bias shifts it vertically. With the logistic sigmoid f_A(x) = 1/(1+e^{-x}), the transition from 0 to 1 is centered at x = 0. Adjusting the bias moves this transition left or right, and the weight magnitude controls the steepness of the transition.
Conclusion
We’ve outlined the core architectural choices for our Perceptron and explained the role of bias nodes. In the next article, we’ll dive into the Python code that brings this design to life.
Industrial robot
- Mastering Python For Loops: Syntax, Examples, and Advanced Patterns
- Expert Overview of M2M Network Architectures for IoT
- CEVA Unveils NeuPro‑S: Next‑Gen AI Processor for Edge Deep Neural Network Inference
- Local Minima in Neural Network Training: Myth or Reality?
- Adding Bias Nodes to a Multilayer Perceptron in Python
- Training Neural Networks with Excel: Building & Validating a Python Multilayer Perceptron
- Building a Multilayer Perceptron Neural Network in Python: A Practical Guide
- Mastering Weight Updates and Backpropagation in Multilayer Perceptrons
- Train Your Multilayer Perceptron: Proven Strategies for Optimal Performance
- Python Network Programming: Master Sockets & Advanced Protocols