


Mastering Weight Updates and Backpropagation in Multilayer Perceptrons
In this article we present the precise equations used for weight‑update calculations and explain how backpropagation enables a multilayer perceptron (MLP) to learn from data.
Welcome to AAC’s comprehensive machine‑learning series.
Catch up on the series so far here:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
We’ve reached the core of neural‑network theory: the computational steps that fine‑tune an MLP’s weights so it can classify input samples accurately. This process is the foundation of the backpropagation algorithm, a cornerstone of modern deep learning.
Updating Weights
Training an MLP is mathematically dense, and terminology varies across sources. The equations below are drawn from Dr. Dustin Stansbury’s clear derivations, making them an excellent reference for both beginners and practitioners.
The diagram shows the architecture we’ll implement in code, and the equations that follow directly map to this structure.
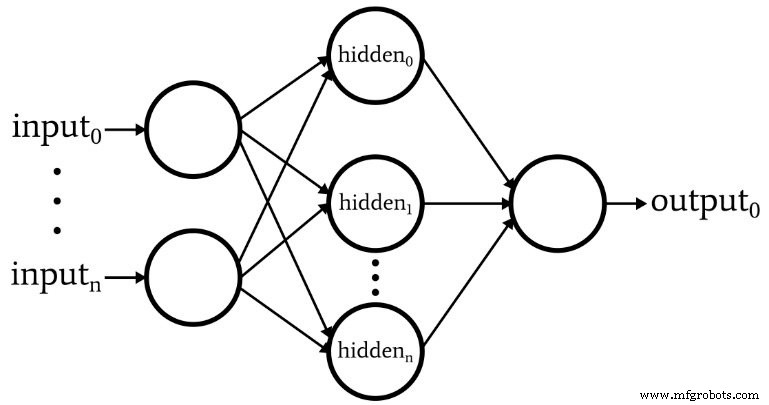
Terminology
- Pre‑activation (SpreA): The weighted sum input to a neuron’s activation function, calculated as a dot product of incoming weights and activations.
- Post‑activation (SpostA): The neuron’s output after applying the activation function fA(·). We use the logistic (sigmoid) function in our examples.
- Weight matrices: In code we label them ItoH (input‑to‑hidden) and HtoO (hidden‑to‑output) to avoid ambiguity.
- Target (T): The correct output for a training sample.
- Learning rate (LR): The step size for weight updates.
- Final error (FE): SpostA,O – T.
- Error signal (SERROR): FE multiplied by the derivative of the output neuron’s activation function.
- Gradient: The contribution of a specific weight to the error signal; we subtract LR × gradient from the current weight.
The accompanying diagram illustrates these concepts in context.
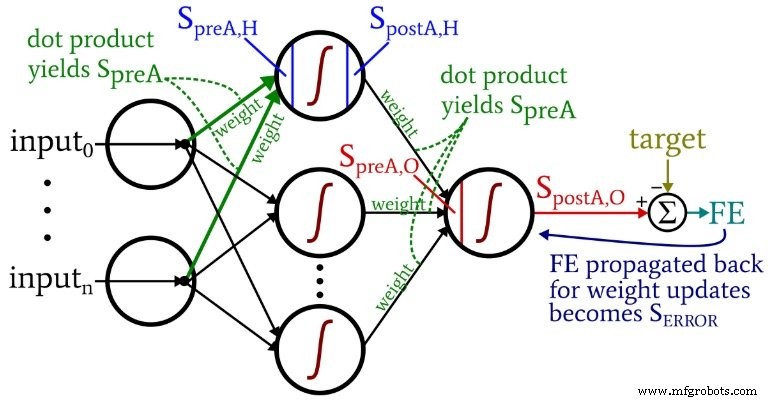
Weight‑update equations result from taking the partial derivative of the summed‑squared error with respect to each weight. For hidden‑to‑output weights:
SERROR = FE × fA'(SpreA,O)
gradientHtoO = SERROR × SpostA,H
weightHtoO ← weightHtoO – (LR × gradientHtoO)
For input‑to‑hidden weights, the error must traverse an additional layer:
gradientItoH = SERROR × weightHtoO × fA'(SpreA,H) × input
weightItoH ← weightItoH – (LR × gradientItoH)
Backpropagation
Backpropagation resolves the hidden‑node dilemma: although input‑to‑hidden weights influence the final output indirectly, we can compute their effect by propagating the error signal backward through the network and scaling it with the outgoing weights and activation derivatives. This technique is fundamental to training deep models.
Conclusion
We’ve unpacked the key equations that drive weight updates and the mechanics of backpropagation in MLPs. These concepts underpin every modern neural‑network application, and mastering them opens the door to advanced modeling. Stay tuned for the next installments in our series, where we’ll dive deeper into architecture design, Python implementation, and validation techniques.
Industrial robot
- 7 Expert Resources to Master Inertia and Inertia Mismatch for Optimal Motor Sizing
- Local Minima in Neural Network Training: Myth or Reality?
- Choosing the Right Number of Hidden Layers and Nodes in a Neural Network
- Training Neural Networks with Excel: Building & Validating a Python Multilayer Perceptron
- Building a Multilayer Perceptron Neural Network in Python: A Practical Guide
- Designing a Flexible Perceptron Neural Network in Python
- Train Your Multilayer Perceptron: Proven Strategies for Optimal Performance
- 5G’s Top Five Challenges: Navigating Spectrum, Cost, Coverage, Devices, and Security
- Elevate Your Expertise with BECKER’s Expert Vacuum Pump Training
- Mandatory Education & Training for Safe Industrial Robot Operations