


Local Minima in Neural Network Training: Myth or Reality?
Understanding the role of local minima in perceptron and multilayer neural‑network training.
In the AAC neural‑network series, we have examined many aspects of multilayer perceptron design and training. Before diving into local minima, review the preceding posts:
- How to Perform Classification Using a Neural Network: What Is the Perceptron?
- How to Use a Simple Perceptron Neural Network Example to Classify Data
- How to Train a Basic Perceptron Neural Network
- Understanding Simple Neural Network Training
- An Introduction to Training Theory for Neural Networks
- Understanding Learning Rate in Neural Networks
- Advanced Machine Learning with the Multilayer Perceptron
- The Sigmoid Activation Function: Activation in Multilayer Perceptron Neural Networks
- How to Train a Multilayer Perceptron Neural Network
- Understanding Training Formulas and Backpropagation for Multilayer Perceptrons
- Neural Network Architecture for a Python Implementation
- How to Create a Multilayer Perceptron Neural Network in Python
- Signal Processing Using Neural Networks: Validation in Neural Network Design
- Training Datasets for Neural Networks: How to Train and Validate a Python Neural Network
- How Many Hidden Layers and Hidden Nodes Does a Neural Network Need?
- How to Increase the Accuracy of a Hidden Layer Neural Network
- Incorporating Bias Nodes into Your Neural Network
- Understanding Local Minima in Neural‑Network Training
Training a neural network is a sophisticated optimization task. While we rarely need to understand every mathematical nuance to build effective models, the phenomenon of local minima remains a critical theoretical consideration.
Why Local Minima Matter
Historically, local minima were viewed as a major obstacle to training, especially for complex input‑output mappings. Recent research—such as studies on loss‑surface geometry (e.g., Choromanska et al., 2015; Dauphin et al., 2014)—suggests that modern architectures and training heuristics reduce the severity of this issue. Nonetheless, understanding local minima helps us appreciate how gradient‑based optimizers navigate high‑dimensional loss landscapes and why certain training strategies can escape suboptimal points.
Defining a Local Minimum
Consider a simple quadratic error surface: f(x, y) = x² + y². Any point that yields the lowest possible error—called the global minimum—is the target of training. In a perfectly convex bowl, gradient descent will always converge to this point regardless of starting position.
In practice, loss surfaces are far from convex. They can contain multiple valleys and plateaus, as illustrated below:
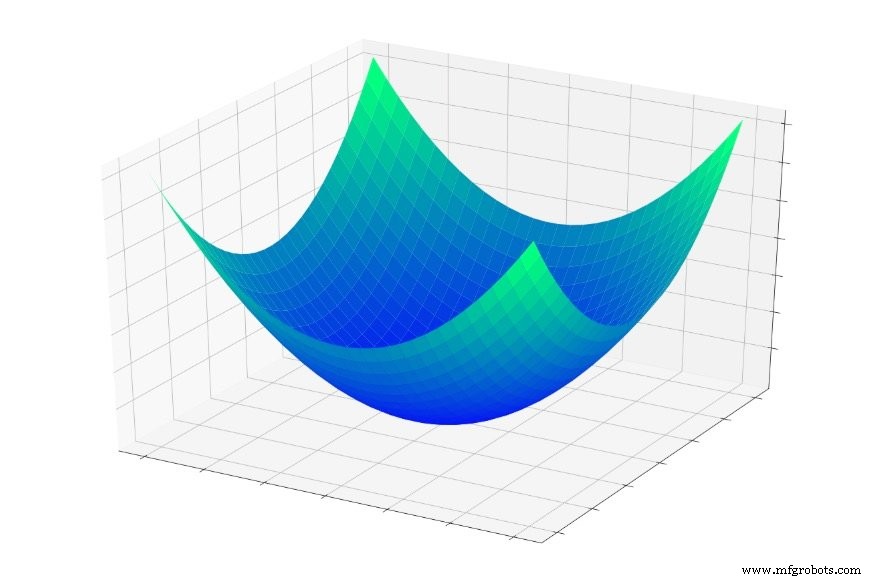
When the optimizer steps into a shallow basin, it may settle in a local minimum—the lowest point within that local region—but not the global one. Without global knowledge, the algorithm cannot “climb” back up to explore deeper valleys.
Do We Truly Need the Global Minimum?
While reaching the global minimum often correlates with lower training error, it is not always synonymous with better generalization. Highly expressive networks that achieve a perfect fit on training data may overfit, reducing performance on unseen samples. In such cases, a well‑located local minimum can provide a more robust solution. Additionally, saddle points—flat regions where gradients vanish in some directions—can pose a greater challenge than simple local minima (Goodfellow et al., 2015).
Practical Implications
Modern training practices mitigate local minima effects through techniques such as stochastic gradient descent, learning rate schedules, momentum, Adam optimizer, and weight initialization schemes. Ensemble methods and regularization (dropout, L2) also help the model avoid overfitting to the global minimum.
Conclusion
Local minima remain a fascinating aspect of neural‑network training. Understanding their impact informs the choice of architecture, optimizer, and regularization strategy. In the next article, we will explore concrete techniques—like learning rate annealing and adaptive optimizers—that guide networks toward desirable minima.
Industrial robot
- Adding Bias Nodes to a Multilayer Perceptron in Python
- Optimizing Hidden Layer Size to Boost Neural Network Accuracy
- Training Neural Networks with Excel: Building & Validating a Python Multilayer Perceptron
- Validating Neural Networks for Reliable Signal Processing
- Building a Multilayer Perceptron Neural Network in Python: A Practical Guide
- Designing a Flexible Perceptron Neural Network in Python
- Mastering Weight Updates and Backpropagation in Multilayer Perceptrons
- Train Your Multilayer Perceptron: Proven Strategies for Optimal Performance
- Training a Basic Perceptron Neural Network with Python: Step‑by‑Step Guide
- Training a Large Neural Network Generates 284,000 kg of CO₂—Equivalent to 5 Cars’ Lifespan Emissions