


Integrating Domain‑Specific Accelerators into RISC‑V for AI, AR/VR, and Vision Workloads
When the RISC‑V ecosystem first emerged, the primary focus was to slash costs in deeply embedded systems that had previously relied on proprietary CPU instruction set architectures (ISAs). As SoCs migrated to FinFET processes, the high mask costs pushed many designers to replace finite state machines with programmable micro‑sequencers built on the RISC‑V ISA. This shift sparked initial excitement and, from 2014 to 2018, led to the commoditization of lightweight RISC‑V cores.
As the architecture matured, RISC‑V gained traction in real‑time, high‑performance applications—particularly as the front end to highly specialized acceleration engines for AI, AR/VR, and computer vision. The open nature of RISC‑V allows designers to extend the ISA, enabling processors to communicate with accelerators via low‑latency co‑processor interfaces rather than traditional memory‑mapped I/O.
The RISC‑V vector extension further empowered these accelerators to process intermediate layers within kernel inner loops. However, achieving this required purpose‑built extensions, such as a custom load instruction that transfers data from an external accelerator into internal vector registers.
These applications demand a programming model that balances efficiency with flexibility. A domain‑specific accelerator—essentially a large multiplier array—is highly efficient but limited in the operations it can perform and in its data‑movement capabilities. In contrast, a general‑purpose CPU like x86 offers maximum flexibility, but most designs cannot afford the >100 W power budget required for such versatility.
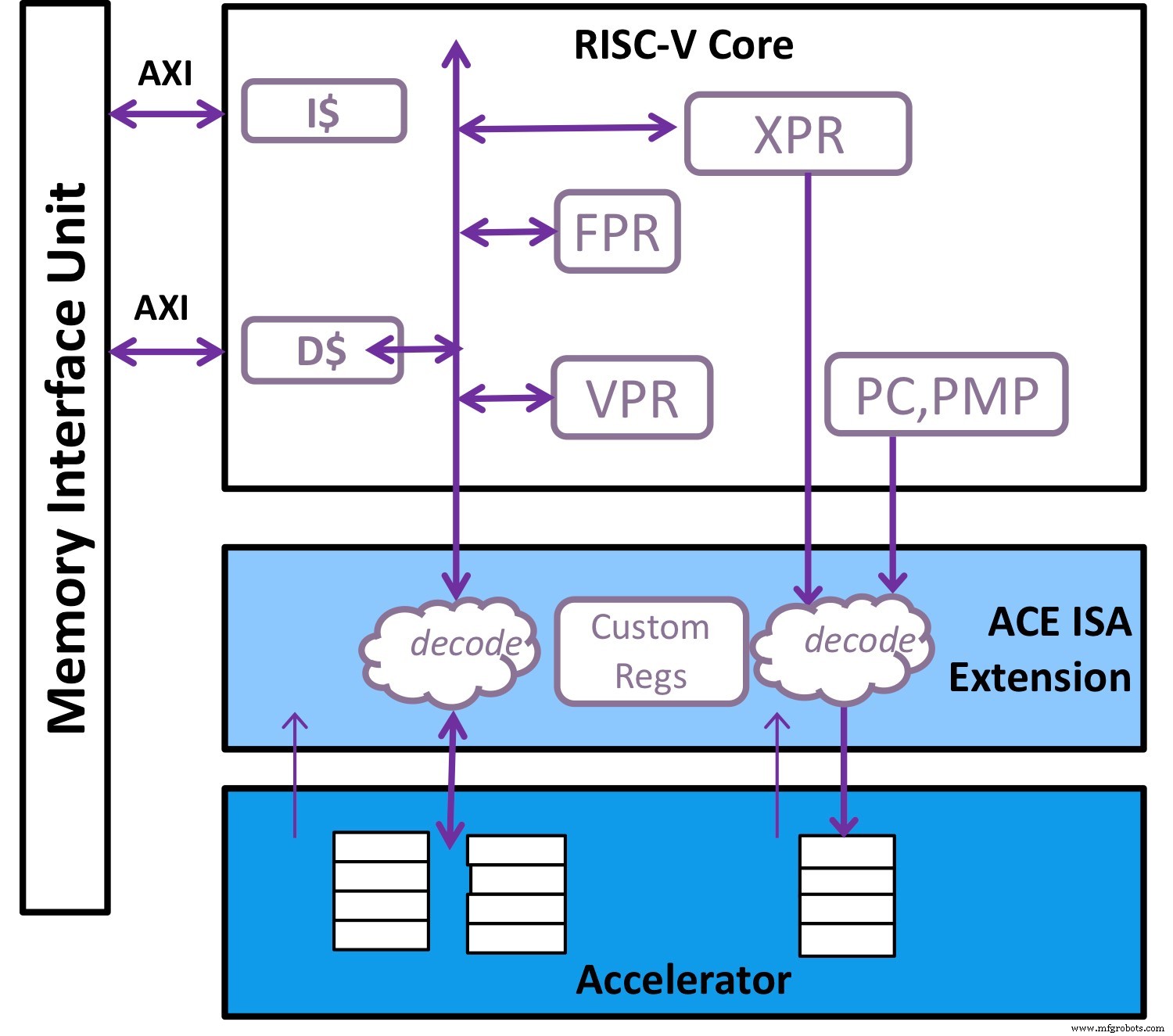
The standard vector extension in RISC‑V augmented with specialized custom instructions is an ideal companion to the accelerator (Image: Andes Technology)
The optimal solution blends the flexibility of a general‑purpose CPU with a task‑specific accelerator, as illustrated above. In RISC‑V, the maturing standard vector extension—augmented with tailored custom instructions—serves as the perfect partner. This synergy has become evident over the past 18 months, as domain‑specific acceleration (DSA) solutions converge onto RISC‑V platforms.
To enable this vision, the accelerator must run its own command set using its dedicated resources, including memory. The RISC‑V core should flatten microcode, packing all necessary control information into a single command. This command set must be aware of the processor’s scalar and vector registers, as well as the accelerator’s own control registers and memory.
When the accelerator needs assistance with specialized data reordering or manipulation, Andes’s architecture employs a vector processing unit (VPU) to handle complex permutations—shifting, gathering, compressing, and expanding. Between layers, kernels often involve intricate data patterns; the VPU supplies the flexibility needed. With both the accelerator and VPU executing massively parallel computations, Andes has introduced hardware to raise memory subsystem bandwidth—prefetching, non‑blocking transactions, and out‑of‑order returns—to meet computational demand.
Andes Technology’s first RISC‑V vector processor, the NX27V, implements the latest V‑extension 0.8 specification. It supports 8‑, 16‑, and 32‑bit integer operations, 16‑ and 32‑bit floating‑point calculations, Bfloat16, and Int4 formats to reduce storage and transfer bandwidth for machine‑learning weights. The vector spec’s flexibility lets designers configure key parameters—vector length, bits per register, SIMD width, and the number of bits processed per cycle.
The NX27V offers a 512‑bit vector length that can expand to 4096 bits by chaining up to eight vector registers. Multiple functional units operate in parallel pipelines, sustaining the throughput required by diverse workloads. In a 512‑bit configuration, the chip reaches 1 GHz in a 7 nm process under worst‑case conditions, occupying just 0.3 mm². For software development, Andes supplies a compiler, debugger, vector libraries, a cycle simulator, and the Clarity visualization tool to analyze and optimize critical loops. The solution is already available through an early‑access program.
Over the past 15 months, demand for high‑performance computing—combining a powerful RISC‑V vector extension, a high‑bandwidth memory subsystem, and an accelerator positioned close to the CPU—has surged. This trend is set to drive broader adoption of RISC‑V and vector processing across the industry.
>> This article was originally published on our sister site, EE Times.
Embedded
- Industrial Internet Reference Architecture v1.8 Released: Introducing the Layered Databus Pattern
- Engineering the Future: Hands‑On Robotics Education with TI's RSLK
- ARMv8 Firmware Architecture: Key Components and Boot Flow in Server Systems
- RISC‑V Based Open‑Source GPU Architecture (RV64X)
- In‑House Production: The Fuse 1 Builds Its Own Parts
- Deep Dive: i.MX RT1170 MCU’s Heterogeneous Graphics Pipeline
- Harnessing Data in the Internet of Reliability: Strategies for Effective Management
- Revealing History: How 3D Printing Transforms Archaeology and Paleontology
- Edge Computing: The Architecture Driving Tomorrow’s Intelligent Networks
- Maximize Your Robot’s Longevity with Expert Maintenance Practices